基于requests库和lxml库编写的爬虫,目标小说网站域名http://www.365kk.cc/ ,类似的小说网站殊途同归,均可采用本文方法爬取。
目标网站 :传送门
本文的目标书籍 :《我的师兄实在太稳健了》
网络爬虫的工作实际上主要分为三个部分:
获取网页内容,通过requests库实现;
解析网页内容,得到其中我们想要的部分,通过lxml库实现;
将解析出的内容储存到文本文档中;
接下来看看我们的需求是什么:
获取目标书籍的基本信息,包括书籍的书名、作者、最近更新时间和简介——这些信息应该都在同一个页面中获取,即目标书籍的主页;
获取目标书籍每一章节的标题和内容——不同章节在不同的页面,不同页面之间可以通过下一页 按序跳转;
正文部分的存储格式应便于阅读,不能把所有文字都堆积在一起,也不能包括除了正文之外的其他无关内容;
因此,我们首先尝试请求书籍的主页,获取基本信息,借此学习请求和解析网页内容的基本方法;紧接着再从书籍的第一章开始,不断地请求“下一页”,直到爬取所有内容,并将它们以合适的格式储存在文本文档中。
首页链接:http://www.365kk.cc/255/255036/
首先,我们观察一下该网站不同的书籍主页:
可以看出:不同书籍的主页具有非常相似的结构 ——标题、作者、最近更新时间、最新章节和正文都在相同的位置上。
如何表征这一位置?这就需要借助python爬虫中常用的网页解析方法——XPath语法 。
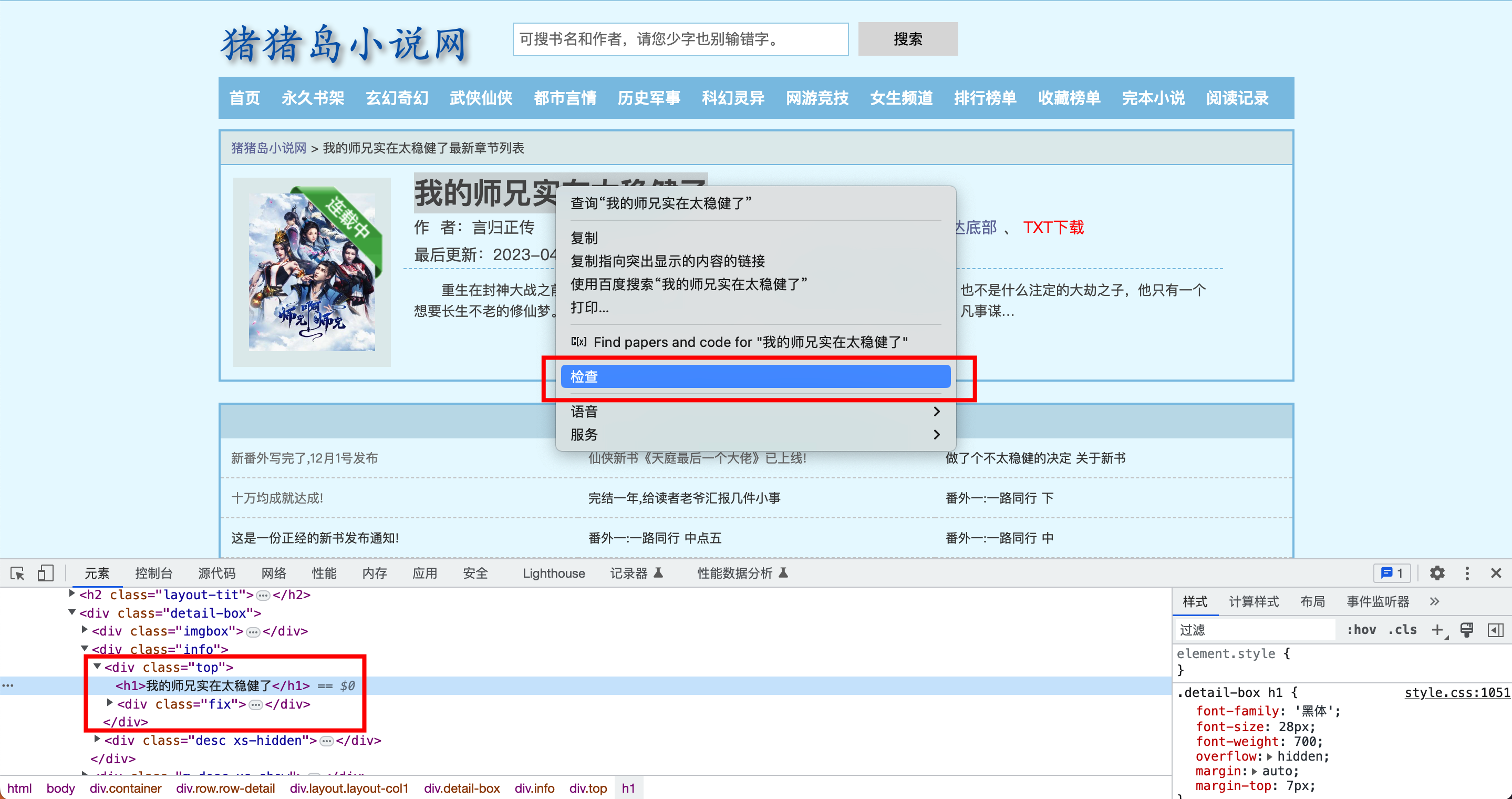
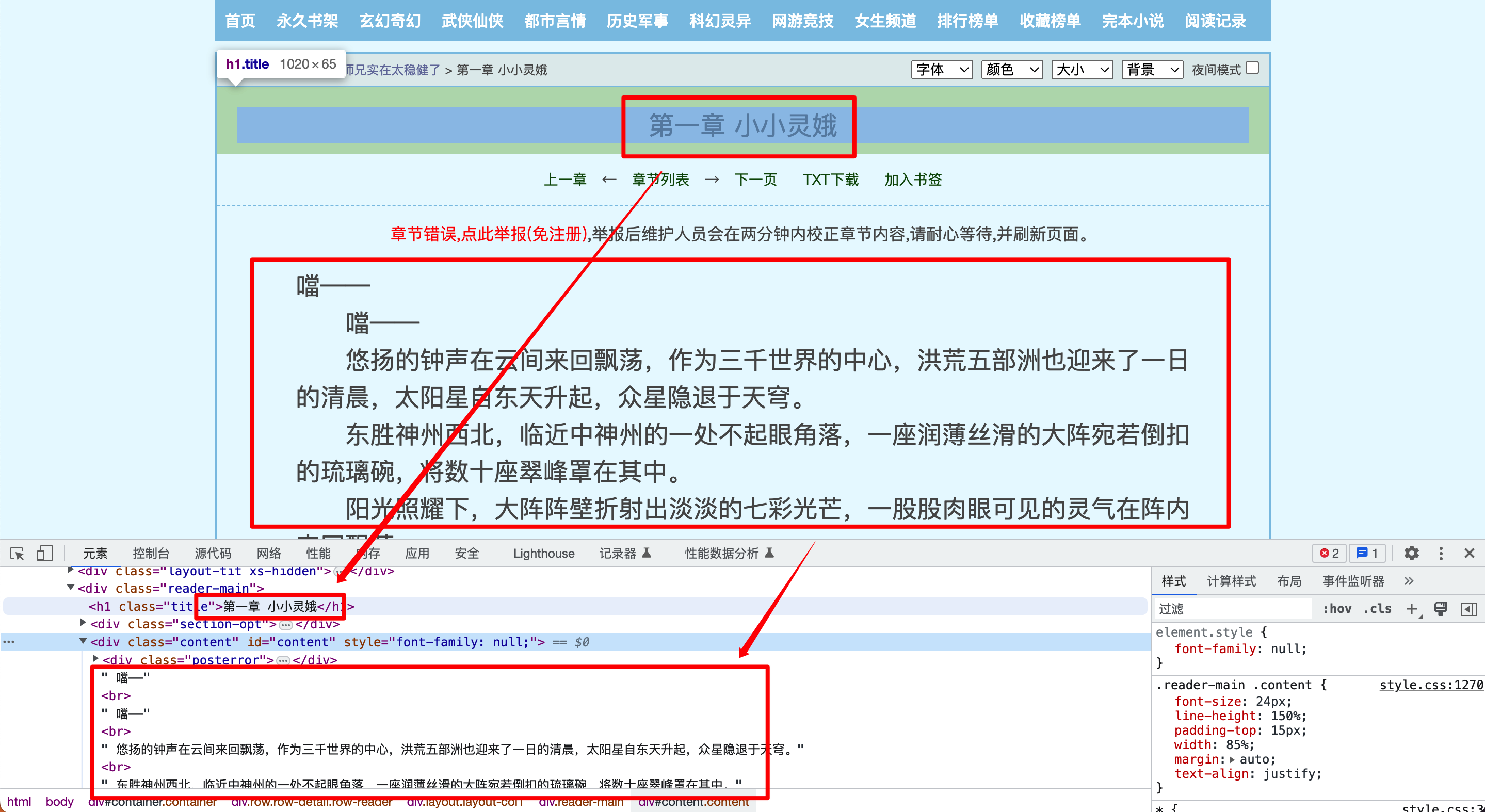
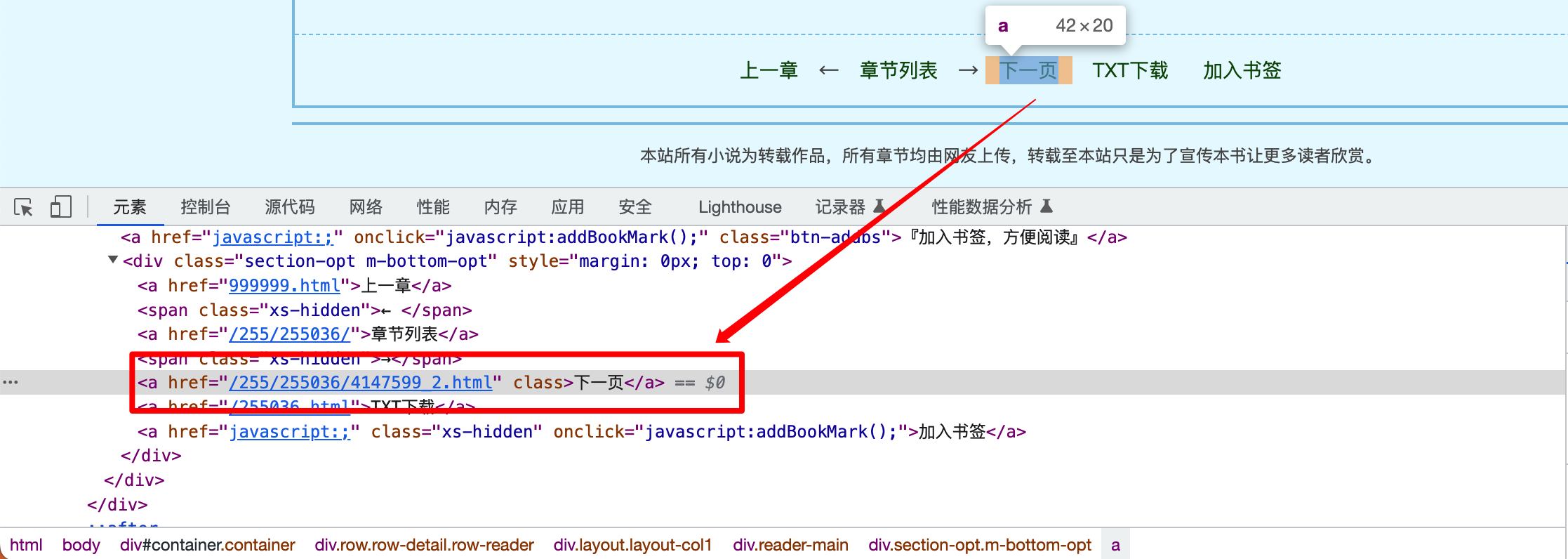
以书名为例,在你的浏览器(以Google Chrome为例)中选中书名,点击右键 -> 检查 :
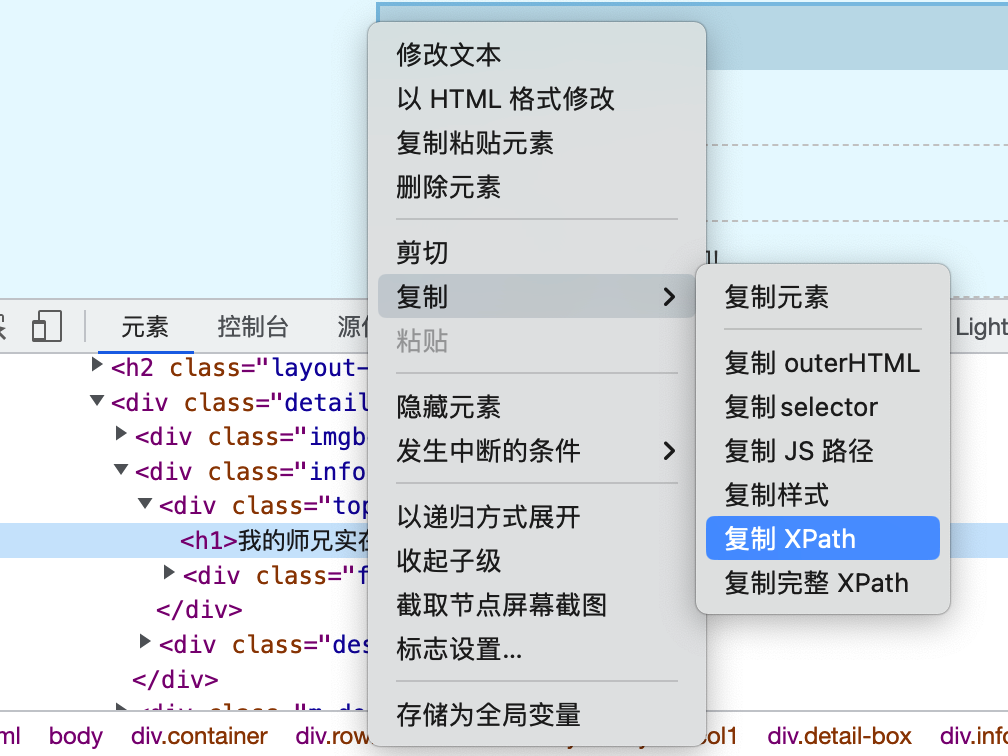
可以看出,浏览器下方弹出了一个窗口,这里显示的就是该页面的源代码,我们选中的内容位于一个<h1>标签中。我们点击右键 -> 复制 -> 复制 XPath ,即可得到书名的XPath路径,也就是书名在网页中的位置。
从书籍的首页中,我们需要获取的信息主要包括:
按照上述方法,分别获取它们的XPath路径,依次如下:
1 2 3 4 /html/body/div[4]/div[1]/div/div/div[2]/div[1]/h1/text() /html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[1]/text() /html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[5]/text() /html/body/div[4]/div[1]/div/div/div[2]/div[2]/text()
现在,我们得到了想要的内容在网页中的位置,只要请求到网页内容,就可以获取指定位置的内容了。
我们使用比较基础的python爬虫网页请求方法:使用 requests 库直接请求。
这里涉及到了简单的反爬虫知识:在请求网页时,我们需要将我们的爬虫伪装成浏览器 ,具体通过添加请求头 headers 实现。
请求头以字典的形式创建,可以包括很多内容,这里只设置四个字段:User-Agent, Cookie, Host 和 Conection。
1 2 3 4 5 6 headers= { 'User-Agent' : '...' , 'Cookie' : '...' , 'Host' : 'www.365kk.cc' , 'Connection' : 'keep-alive' }
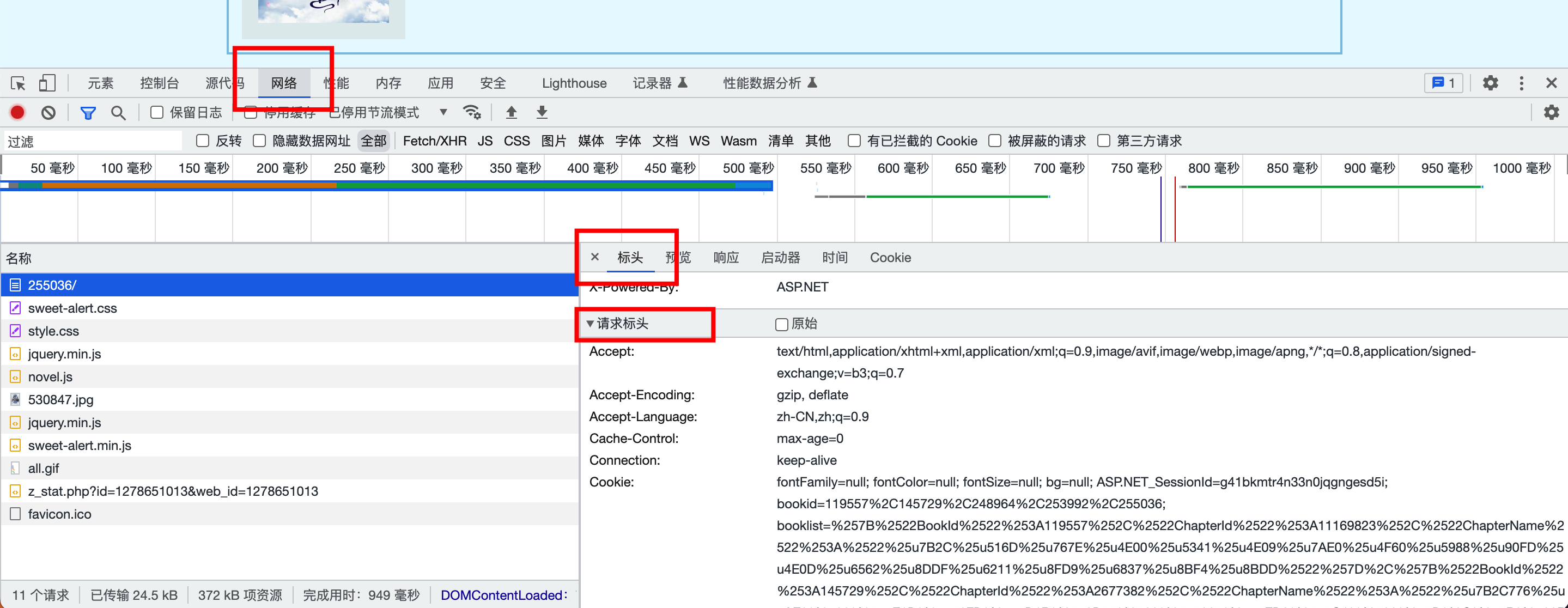
既然是为了伪装成浏览器,相关字段的内容当然要从浏览器中获取。
在刚才打开的页面中,我们点击 网络 (英文版是 Network ),刷新页面,找到其中的第一个文件 255036/ ,打开标头 -> 请求标头 ,即可得到我们想要的字段数据,如下图所示。
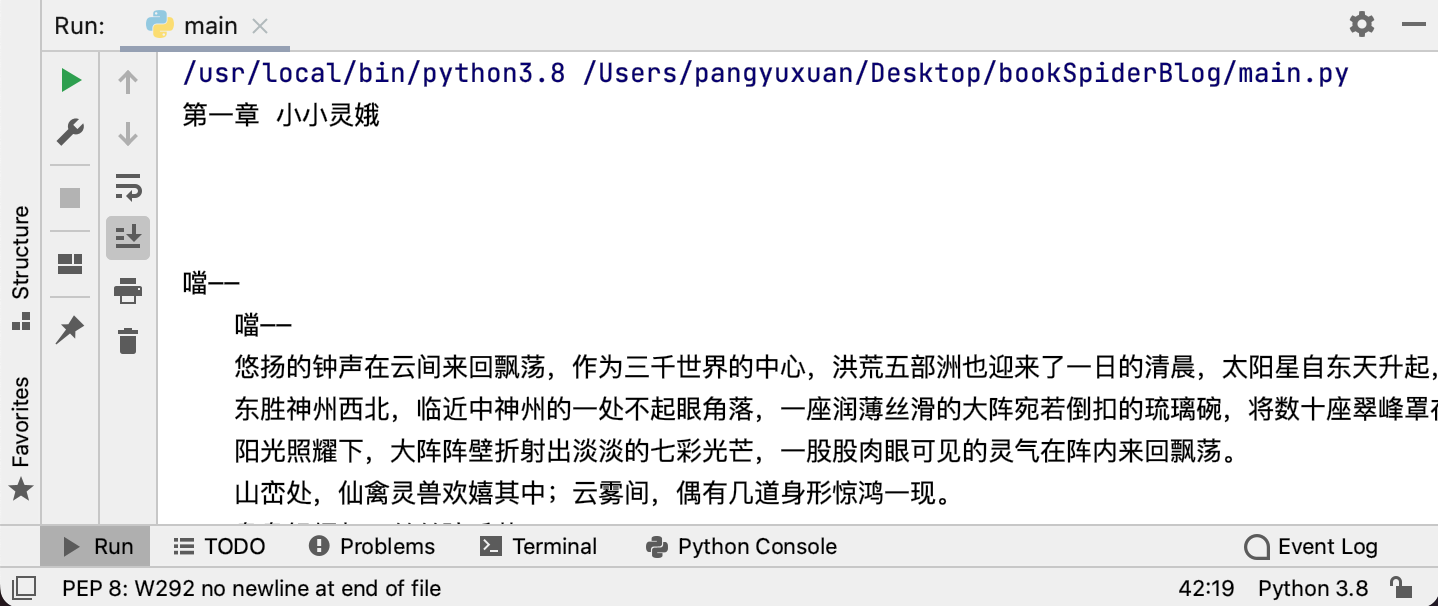
使用 requests 库的 get 方法请求网站内容,将其解码为文本形式,输出结果验证,完整的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 import requestsheaders= { 'User-Agent' : '...' , 'Cookie' : '...' , 'Host' : 'www.365kk.cc' , 'Connection' : 'keep-alive' } main_url = "http://www.365kk.cc/255/255036/" main_resp = requests.get(main_url, headers=headers) main_text = main_resp.content.decode('utf-8' ) print (main_text)
运行代码前,需要向 headers 中填入你自己浏览器的信息。
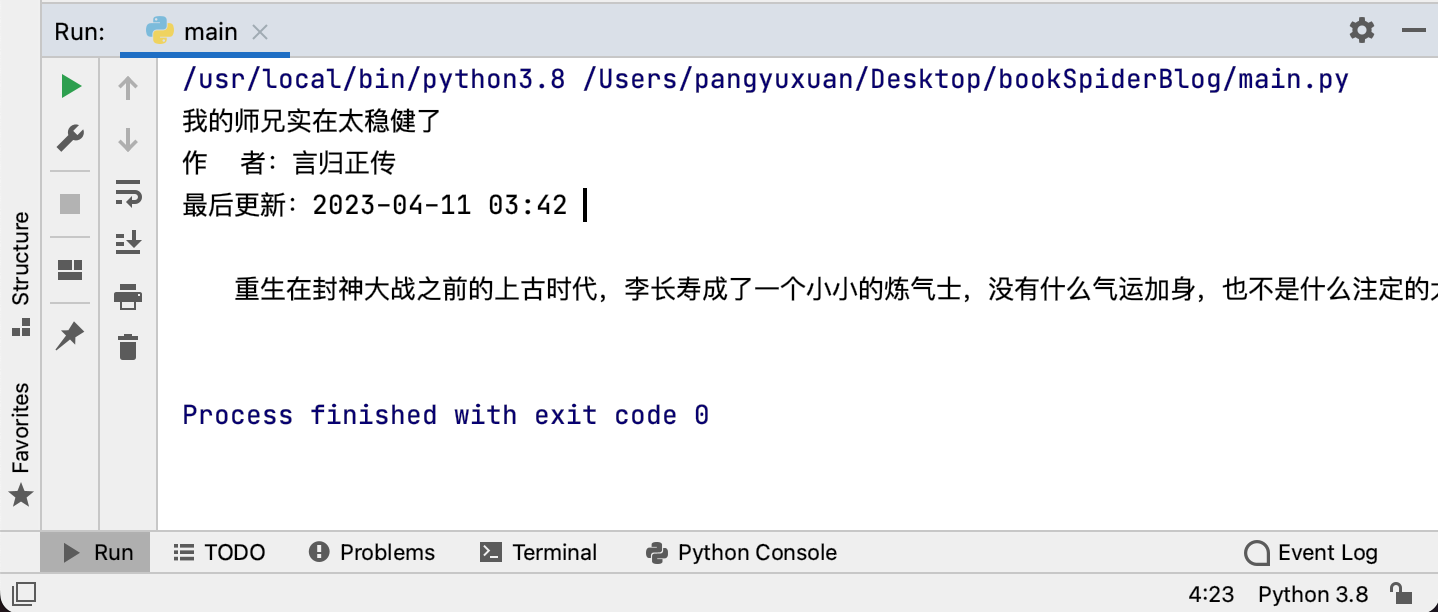
输出结果如下:
可以看出,我们成功请求到了网站内容,接下来只需对其进行解析,即可得到我们想要的部分。
我们使用 lxml 库来解析网页内容,具体方法为将文本形式的网页内容创建为可解析的元素,再按照XPath路径访问其中的内容,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import requestsfrom lxml import etreeheaders= { 'User-Agent' : '...' , 'Cookie' : '...' , 'Host' : 'www.365kk.cc' , 'Connection' : 'keep-alive' } main_url = "http://www.365kk.cc/255/255036/" main_resp = requests.get(main_url, headers=headers) main_text = main_resp.content.decode('utf-8' ) main_html = etree.HTML(main_text) bookTitle = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/h1/text()' )[0 ] author = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[1]/text()' )[0 ] update = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[5]/text()' )[0 ] introduction = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[2]/text()' )[0 ] print (bookTitle)print (author)print (update)print (introduction)
输出结果如下:
至此,我们已经学会了基本的网页请求方法 ,并学会了如何获取目标页面中的特定内容 。
接下来,我们开始爬取正文。首先尝试获取单个页面的数据,再尝试设计一个循环,依次获取所有正文数据。
以第一章为例,链接:http://www.365kk.cc/255/255036/4147599.html ,获取章节标题和正文的XPath路径如下:
1 2 //*[@id="container"]/div/div/div[2]/h1/text() //*[@id="content"]/text()
按照与上文一致的方法请求并解析网页内容,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import requestsfrom lxml import etreeheaders= { 'User-Agent' : '...' , 'Cookie' : '...' , 'Host' : 'www.365kk.cc' , 'Connection' : 'keep-alive' } url = 'http://www.365kk.cc/255/255036/4147599.html' resp = requests.get(url, headers) text = resp.content.decode('utf-8' ) html = etree.HTML(text) title = html.xpath('//*[@id="container"]/div/div/div[2]/h1/text()' )[0 ] contents = html.xpath('//*[@id="content"]/text()' ) print (title)for content in contents: print (content)
输出结果如下:
可以看出,我们成功获取了小说第一章第一页的标题和正文部分,接下来我们将它储存在一个txt文本文档中,文档命名为之前获取的书名 bookTitle.txt,完整的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import requestsfrom lxml import etreeheaders= { 'User-Agent' : '...' , 'Cookie' : '...' , 'Host' : 'www.365kk.cc' , 'Connection' : 'keep-alive' } main_url = "http://www.365kk.cc/255/255036/" main_resp = requests.get(main_url, headers=headers) main_text = main_resp.content.decode('utf-8' ) main_html = etree.HTML(main_text) bookTitle = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/h1/text()' )[0 ] author = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[1]/text()' )[0 ] update = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[5]/text()' )[0 ] introduction = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[2]/text()' )[0 ] url = 'http://www.365kk.cc/255/255036/4147599.html' resp = requests.get(url, headers) text = resp.content.decode('utf-8' ) html = etree.HTML(text) title = html.xpath('//*[@id="container"]/div/div/div[2]/h1/text()' )[0 ] contents = html.xpath('//*[@id="content"]/text()' ) with open (bookTitle + '.txt' , 'w' , encoding='utf-8' ) as f: f.write(title) for content in contents: f.write(content) f.close()
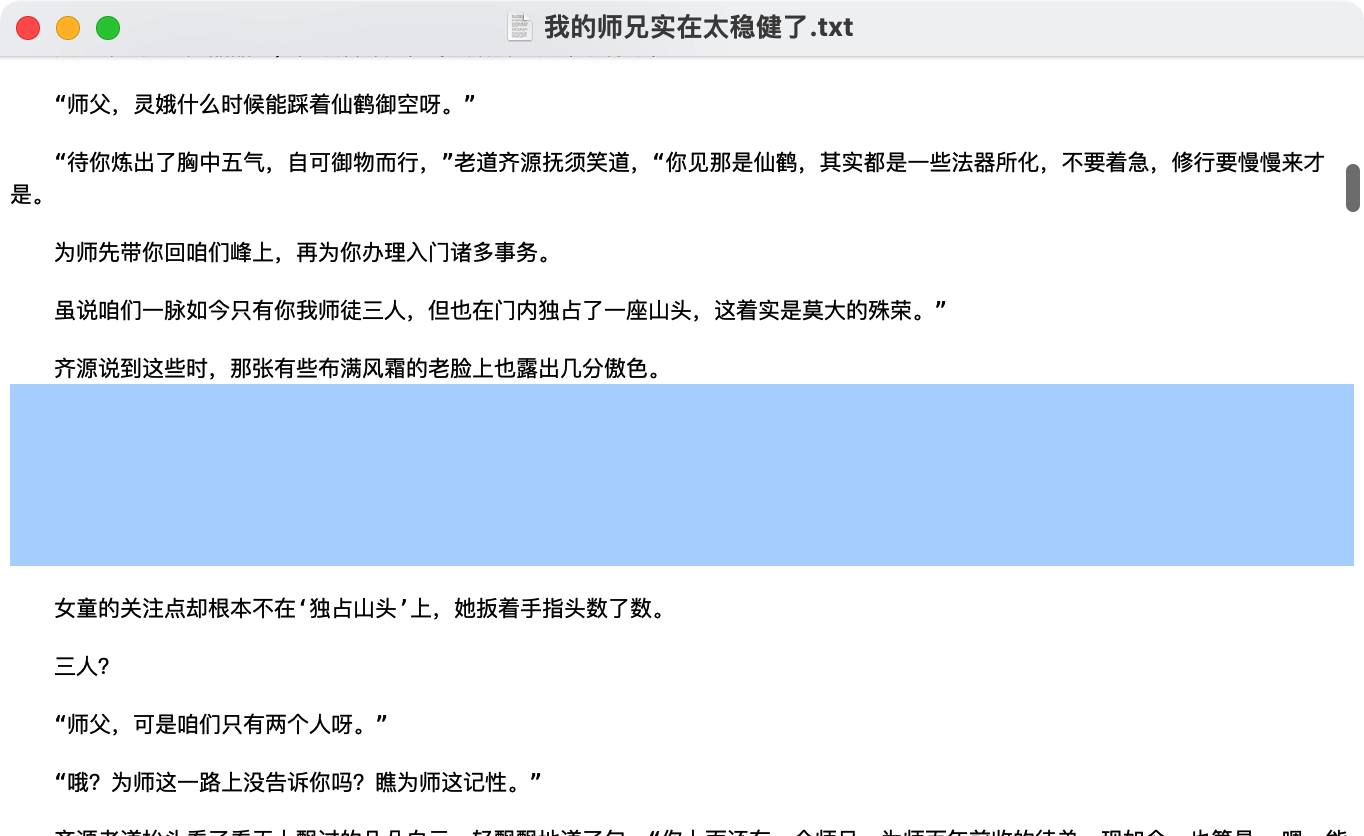
运行结束后,可以看到在代码文件的同路径中,已经生成了一个文本文档:
打开该文档,可以看到储存好的内容:
储存好的内容中,大段的文字堆积在一起,而原文确实有着段落的区分,因此我们在储存文件时,每储存一段,就写入两个换行符 \n,使格式更便于阅读:
1 2 3 4 5 6 with open (bookTitle + '.txt' , 'w' , encoding='utf-8' ) as f: f.write(title) for content in contents: f.write(content) f.write('\n\n' ) f.close()
至此,我们已经完成了单个页面的数据爬取和存储,接下来只要设计循环,实现顺序爬取所有页面即可。
关于文件读取的类型
本文中,用到的文件读取类型主要有:
类型 含义 使用示例 'w'清空原文档,重新写入文档 open(filename, 'w')'r'仅读取文档,不改变其内容 open(filename, 'r')'a'在原文档之后追加内容 open(filename, 'a')
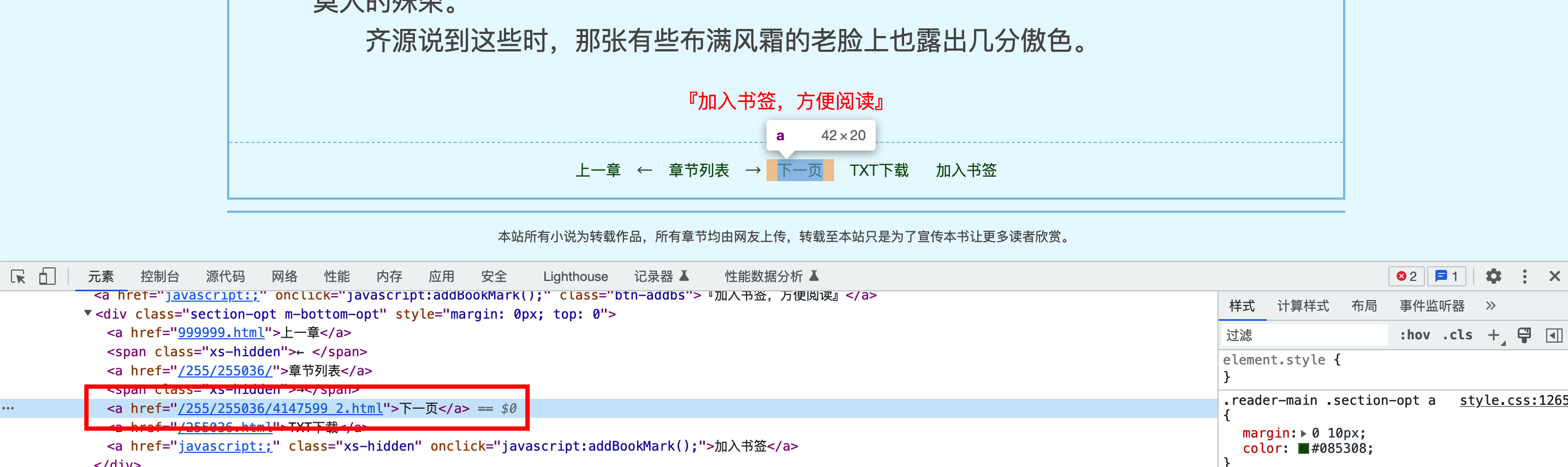
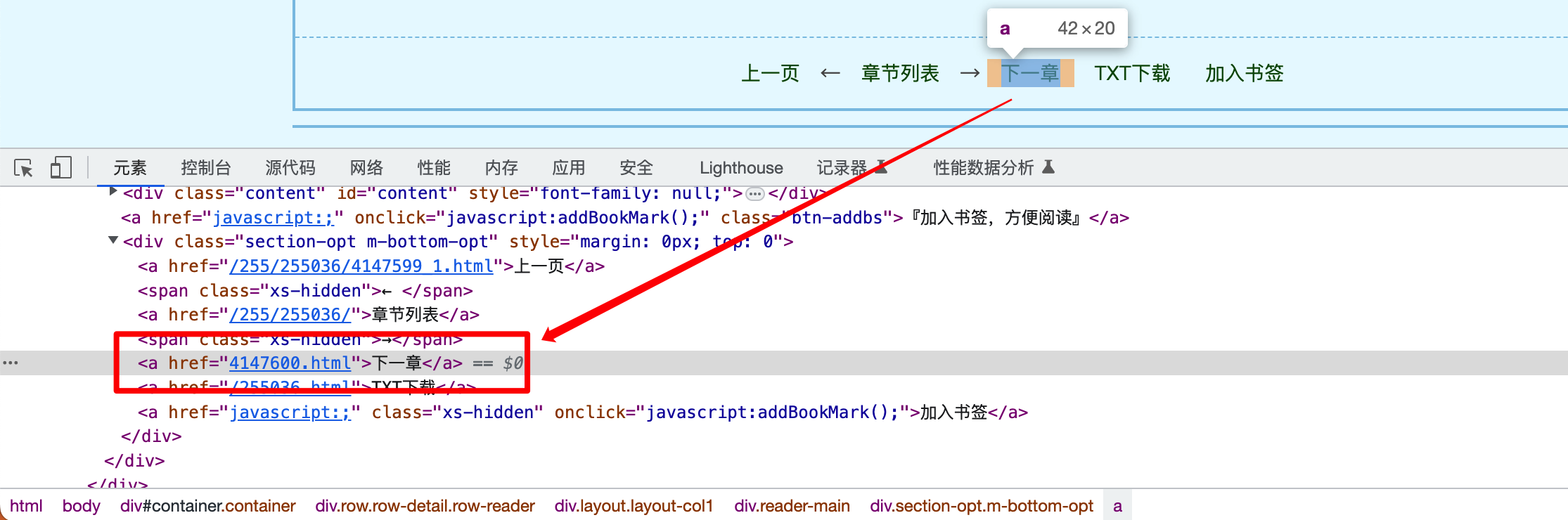
我们注意到,正文的每个页面底部,都有一个按钮 下一页 ,其在网页中的结构为:
我们在XPath路径的末尾添加 @href 用于获取属性 href 的值:
1 //*[@id="container"]/div/div/div[2]/div[3]/a[3]/@href
这里有一个小细节需要注意
我们获取到的属性值在不同页面可能是不一样的 ,比如:
第一章第一页中,下一页 指向的链接为/255/255036/4147599_2.html 第一章第二页中,下一页 指向的链接为4147600.html 观察不同页面的链接,可以看出前缀是一致的,区别仅在后缀上 ,比如第一章第一页和第一章第二页的链接分别为:
1 2 http://www.365kk.cc/255/255036/4147599.html http://www.365kk.cc/255/255036/4147599_2.html
因此,我们只需要获取 下一页 的链接后缀,再与前缀拼接,即可获得完整的访问链接。
编写一个函数 next_url() 实现上述功能:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def next_url (next_url_element ): nxturl = 'http://www.365kk.cc/255/255036/' index = next_url_element.rfind('/' ) + 1 nxturl += next_url_element[index:] return nxturl url1 = '/255/255036/4147599_2.html' url2 = '4147600.html' print (next_url(url1))print (next_url(url2))
输出如下所示:
在爬取某一页面的内容后,我们获取下一页的链接,并请求该链接指向的网页 ,重复这一过程直到全部爬取完毕为止,即可实现正文的爬取。
在这一过程中,需要注意的问题有:
某一章节的内容可能分布在多个页面中,每个页面的章节标题是一致的 ,这一标题只需存储一次;
请求网页内容的频率不宜过高 ,频繁地使用同一IP地址请求网页,会触发站点的反爬虫机制,禁止你的IP继续访问网站;爬取一次全文耗时较长,为了便于测试,我们需要先尝试爬取少量内容,代码调试完成后再爬取全文;
爬取的起点为第一章第一页,爬取的终点可以自行设置;
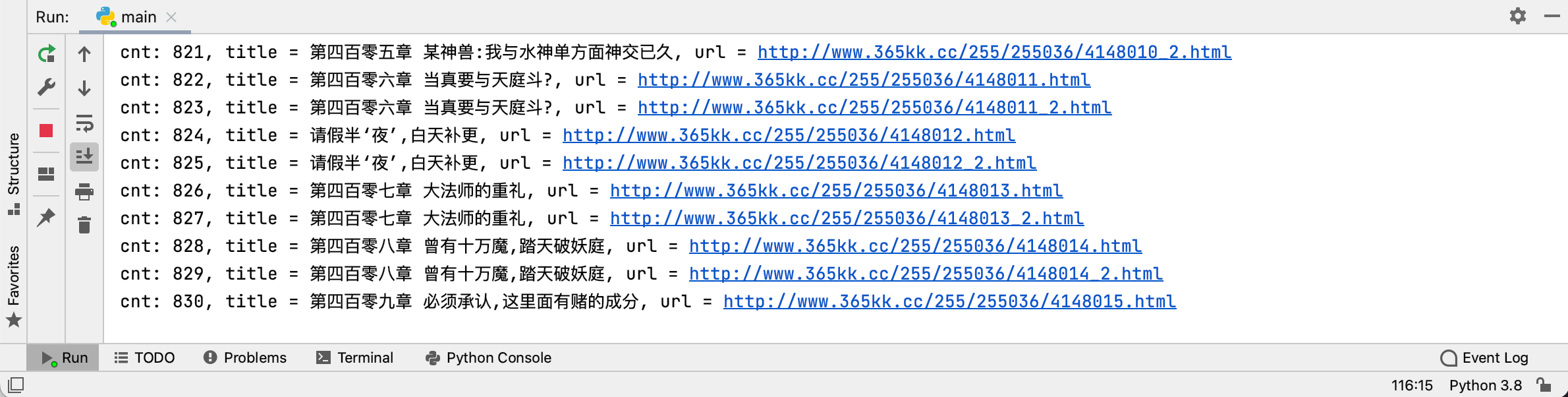
按照上述思想,爬取前6个页面作为测试,完整的代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 import requestsfrom lxml import etreeimport timeimport randomdef next_url (next_url_element ): nxturl = 'http://www.365kk.cc/255/255036/' index = next_url_element.rfind('/' ) + 1 nxturl += next_url_element[index:] return nxturl headers= { 'User-Agent' : '...' , 'Cookie' : '...' , 'Host' : 'www.365kk.cc' , 'Connection' : 'keep-alive' } main_url = "http://www.365kk.cc/255/255036/" main_resp = requests.get(main_url, headers=headers) main_text = main_resp.content.decode('utf-8' ) main_html = etree.HTML(main_text) bookTitle = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/h1/text()' )[0 ] author = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[1]/text()' )[0 ] update = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[5]/text()' )[0 ] introduction = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[2]/text()' )[0 ] maxPages = 6 cnt = 0 lastTitle = '' url = 'http://www.365kk.cc/255/255036/4147599.html' endurl = 'http://www.365kk.cc/255/255036/4148385.html' while url != endurl: cnt += 1 if cnt > maxPages: break resp = requests.get(url, headers) text = resp.content.decode('utf-8' ) html = etree.HTML(text) title = html.xpath('//*[@class="title"]/text()' )[0 ] contents = html.xpath('//*[@id="content"]/text()' ) print ("cnt: {}, title = {}, url = {}" .format (cnt, title, url)) with open (bookTitle + '.txt' , 'a' , encoding='utf-8' ) as f: if title != lastTitle: f.write(title) lastTitle = title for content in contents: f.write(content) f.write('\n\n' ) f.close() next_url_element = html.xpath('//*[@class="section-opt m-bottom-opt"]/a[3]/@href' )[0 ] url = next_url(next_url_element) sleepTime = random.randint(2 , 5 ) time.sleep(sleepTime) print ("complete!" )
运行结果如下:
观察我们得到的文本文档,可以发现如下问题:
缺乏书籍信息 ,如之前获取的书名、作者、最后更新时间和简介;切换页面时,尤其是同一章节的不同页面之间空行过多 ;
为了解决这些问题,我们编写一个函数 clean_data() 来实现数据清洗,代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 def clean_data (filename, info ): """ :param filename: 原文档名 :param info: [bookTitle, author, update, introduction] """ print ("\n==== 数据清洗开始 ====" ) new_filename = 'new' + filename f_old = open (filename, 'r' , encoding='utf-8' ) f_new = open (new_filename, 'w' , encoding='utf-8' ) f_new.write('== 《' + info[0 ] + '》\r\n' ) f_new.write('== ' + info[1 ] + '\r\n' ) f_new.write('== ' + info[2 ] + '\r\n' ) f_new.write("=" * 10 ) f_new.write('\r\n' ) f_new.write('== ' + info[3 ] + '\r\n' ) f_new.write("=" * 10 ) f_new.write('\r\n' ) lines = f_old.readlines() empty_cnt = 0 for line in lines: if line == '\n' : empty_cnt += 1 if empty_cnt >= 2 : continue else : empty_cnt = 0 if line.startswith("\u3000\u3000" ): line = line[2 :] f_new.write(line) elif line.startswith("第" ): f_new.write("\r\n" ) f_new.write("-" * 20 ) f_new.write("\r\n" ) f_new.write(line) else : f_new.write(line) f_old.close() f_new.close()
清洗后的文档中,每段段首无缩进,段与段之间仅空一行,不同章节之间插入20个字符 - 用以区分,上述问题得以解决。
需先填入自己浏览器的 headers 信息才可以直接运行哦!
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 import requestsfrom lxml import etreeimport timeimport randomdef next_url (next_url_element ): nxturl = 'http://www.365kk.cc/255/255036/' index = next_url_element.rfind('/' ) + 1 nxturl += next_url_element[index:] return nxturl def clean_data (filename, info ): """ :param filename: 原文档名 :param info: [bookTitle, author, update, introduction] """ print ("\n==== 数据清洗开始 ====" ) new_filename = 'new' + filename f_old = open (filename, 'r' , encoding='utf-8' ) f_new = open (new_filename, 'w' , encoding='utf-8' ) f_new.write('== 《' + info[0 ] + '》\r\n' ) f_new.write('== ' + info[1 ] + '\r\n' ) f_new.write('== ' + info[2 ] + '\r\n' ) f_new.write("=" * 10 ) f_new.write('\r\n' ) f_new.write('== ' + info[3 ] + '\r\n' ) f_new.write("=" * 10 ) f_new.write('\r\n' ) lines = f_old.readlines() empty_cnt = 0 for line in lines: if line == '\n' : empty_cnt += 1 if empty_cnt >= 2 : continue else : empty_cnt = 0 if line.startswith("\u3000\u3000" ): line = line[2 :] f_new.write(line) elif line.startswith("第" ): f_new.write("\r\n" ) f_new.write("-" * 20 ) f_new.write("\r\n" ) f_new.write(line) else : f_new.write(line) f_old.close() f_new.close() headers= { 'User-Agent' : '...' , 'Cookie' : '...' , 'Host' : 'www.365kk.cc' , 'Connection' : 'keep-alive' } main_url = "http://www.365kk.cc/255/255036/" main_resp = requests.get(main_url, headers=headers) main_text = main_resp.content.decode('utf-8' ) main_html = etree.HTML(main_text) bookTitle = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/h1/text()' )[0 ] author = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[1]/text()' )[0 ] update = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[1]/div/p[5]/text()' )[0 ] introduction = main_html.xpath('/html/body/div[4]/div[1]/div/div/div[2]/div[2]/text()' )[0 ] maxPages = 6 cnt = 0 lastTitle = '' url = 'http://www.365kk.cc/255/255036/4147599.html' endurl = 'http://www.365kk.cc/255/255036/4148385.html' while url != endurl: cnt += 1 resp = requests.get(url, headers) text = resp.content.decode('utf-8' ) html = etree.HTML(text) title = html.xpath('//*[@class="title"]/text()' )[0 ] contents = html.xpath('//*[@id="content"]/text()' ) print ("cnt: {}, title = {}, url = {}" .format (cnt, title, url)) print (contents) with open (bookTitle + '.txt' , 'a' , encoding='utf-8' ) as f_new: if title != lastTitle: f_new.write(title) lastTitle = title for content in contents: f_new.write(content) f_new.write('\n\n' ) f_new.close( ) next_url_element = html.xpath('//*[@class="section-opt m-bottom-opt"]/a[3]/@href' )[0 ] url = next_url(next_url_element) sleepTime = random.randint(2 , 5 ) time.sleep(sleepTime) clean_data(bookTitle + '.txt' , [bookTitle, author, update, introduction]) print ("complete!" )
爬取过程如图:
上述的开发流程基本上是想到哪写到哪,所有代码都堆在一个文件里,可读性较差 。
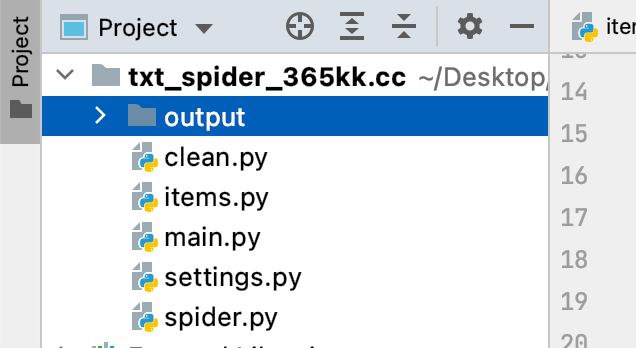
可以参考Scrapy框架的规则,将不同作用的变量和代码分配到不同的文件中,提高整个项目的可读性。
参考的文件结构如图所示:
其中:
output 用于存储爬虫输出的文本文档clean.py 用于实现数据清洗items.py 用于定义需要爬取的变量main.py 是整个项目的主函数settings.py 用于定义请求头、请求间隔、代理IP等spider.py 用于实现爬虫的基本逻辑