ps . 案例制作时的操作环境是MacOS,如果是windows用户,下文中提到的“终端”指的就是cmd命令行窗口。
pps . 本文省略了安装过程,尚未安装scrapy的用户可以直接在pycharm的preference内搜索安装。
目标网站 :传送门
任务 :使用Scrapy框架爬虫,爬取“推荐”中共10页的古诗题目、作者、朝代和内容
ps. 各类教程都拿它举例子,古诗文网好惨
创建Scrapy爬虫项目需要在终端 中进行
先打开一个文件路径,即你希望的爬虫文件存放路径,比如我放在创建好的spidertest 文件夹中:
1 cd /Users/pangyuxuan/spidertest # 这是文件夹路径
使用命令创建项目:
1 scrapy startproject [项目名称]
创建爬虫:
1 2 cd [项目名称] # 先进入项目路径scrapy genspider [爬虫名称] [目标域名] # 再创建爬虫文件
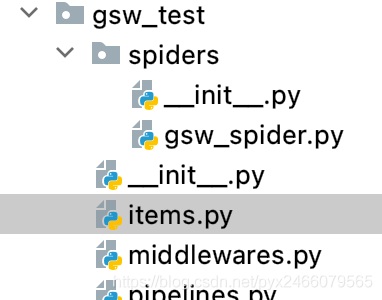
至此你已经创建好了scrapy爬虫文件,它应该长这样:
其中[项目名称]为gsw_test,[爬虫名称]为gsw_spider
综上,创建一个基本的scrapy爬虫文件,一共在终端的命令行中输入了4行代码:
1 2 3 4 5 cd /Users/pangyuxuan/spidertest # 打开一个文件路径,作为爬虫的存放路径scrapy startproject gsw_test # 创建scrapy项目,名为gsw_test cd gsw_test # 打开项目路径scrapy genspider gsw_spider https://www.gushiwen.org # 创建scrapy爬虫,爬虫名为gsw_spider,目标域名为 https://www.gushiwen.org
后续的编写还是依赖pycharm,所以在pycharm中打开项目文件:
其中各个文件的作用如下:
settings.py:用来配置爬虫 的,比如设置User-Agent、下载延时、ip代理。middlewares.py:用来定义中间件。items.py:用来提前定义好需要下载的数据字段 。pipelines.py:用来保存数据 。scrapy.cfg:用来配置项目 。
以下内容请按顺序阅读并实现
settings.py先在settings.py中做两项工作:
设置robots.txt协议为“不遵守”
robots.txt是一个互联网爬虫许可协议 ,默认是True(遵守协议),如果遵守的话大部分网站都无法进行爬取 ,所以先把这个协议的状态设为不遵守
ps. 所以这个协议的意义是什么。。。
配置请求头(设置user-agent)
1 2 3 4 5 6 DEFAULT_REQUEST_HEADERS = { 'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8' , 'Accept-Language' : 'en' , 'user-agent' : '我自己的ua' }
gsw_spider.py1 2 3 4 5 6 7 8 9 import scrapyclass GswSpiderSpider (scrapy.Spider): name = 'gsw_spider' allowed_domains = ['https://www.gushiwen.org' ] start_urls = ['http://https://www.gushiwen.org/' ] def parse (self, response ):
目前的爬虫起始网页start_urls是自动生成的,我们把它换成古诗文网的第一页
1 start_urls = ['https://www.gushiwen.cn/default_1.aspx' ]
为了使打印出来的结果更加直观,我们编写myprint函数如下:
1 2 3 4 def myprint (self,value ): print ("=" *30 ) print (value) print ("=" *30 )
然后我们尝试打印一下当前爬取到的内容,应该为古诗文网第一页的信息。
目前为止,gsw_spider.py被改成了这样:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import scrapyclass GswSpiderSpider (scrapy.Spider): name = 'gsw_spider' allowed_domains = ['https://www.gushiwen.org' ] start_urls = ['https://www.gushiwen.cn/default_1.aspx' ] def myprint (self,value ): print ("=" *30 ) print (value) print ("=" *30 ) def parse (self, response ): self .myprint(response.text)
scrapy爬虫需要在终端里输入命令来运行 ,输入命令如下:
方便起见,我们在项目目录里新建一个start.py,通过cmdline库里的函数来向终端发送命令,这样就不用不停地切换窗口了 ,而且运行结果可以在pycharm里直接展现 ,这样就与我们之前学的爬虫一样了。
后续我们无论修改哪个代码,都是运行start.py这个文件。
1 2 3 from scrapy import cmdlinecmds = ['scrapy' ,'crawl' ,'gsw_spider' ] cmdline.execute(cmds)
点击运行,可以在运行窗口中看到结果:
截至目前为止,我们已经获取了网页源代码 ,接下来的工作就是从源代码中解析想要的数据 了。
无需导入新的库,Scrapy框架为我们内置了许多函数,使我们仍可以用之前学习的数据解析知识(xpath、bs4和正则表达式)来完成数据提取。
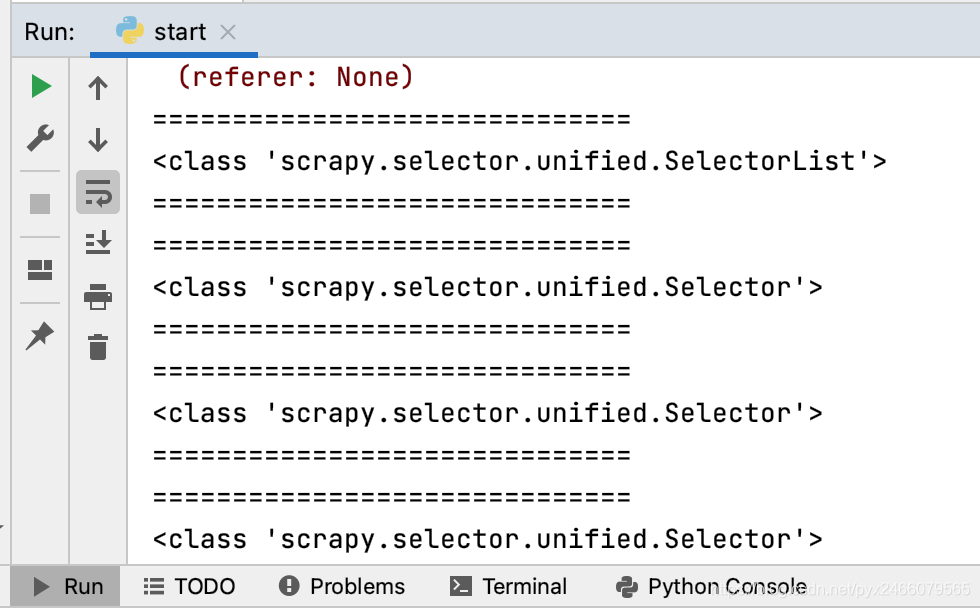
使用xpath语法提取数据,返回的结果是选择器列表类型 SelectorList,选择器列表里包含很多选择器 Selector,即:
response.xpath返回的是SelectorList对象SelectorList存储的是Selector对象
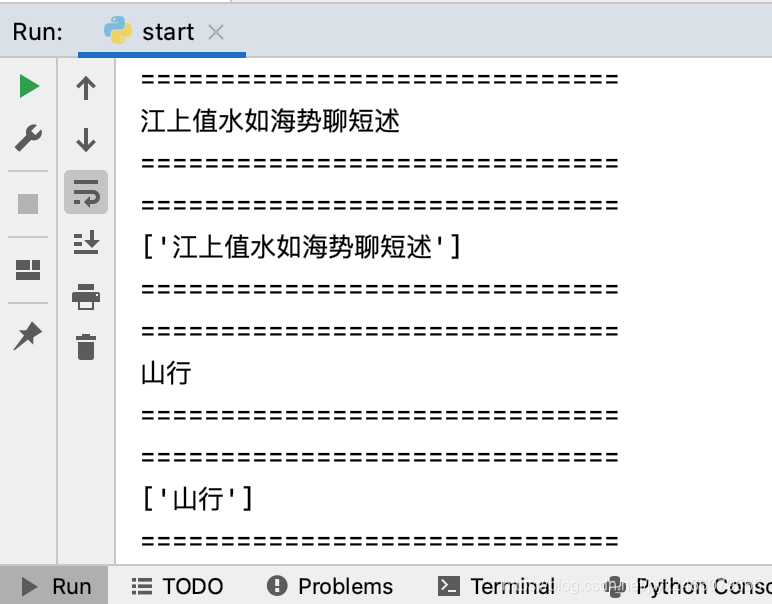
我们获取一下所有包含古诗标题的标签,输出返回值类型,以验证上面的结论:
1 2 3 4 5 def parse (self, response ): gsw_divs = response.xpath("//div[@class='left']/div[@class='sons']" ) self .myprint(type (gsw_divs)) for gsw_div in gsw_divs : self .myprint(type (gsw_div))
运行结果:
使用get()或getall()函数从选择器类型的数据中提取需要的数据 :
get()返回选择器的第一个值(字符串类型)
getall()返回选择器的所有值(列表类型)
1 2 3 4 5 for gsw_div in gsw_divs : title_get = gsw_div.xpath(".//b/text()" ).get() title_getall = gsw_div.xpath(".//b/text()" ).getall() self .myprint(title_get) self .myprint(title_getall)
输出:
我们共提取标题、朝代、作者、内容四部分信息,gsw_spider.py代码如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import scrapyclass GswSpiderSpider (scrapy.Spider): name = 'gsw_spider' allowed_domains = ['https://www.gushiwen.org' ] start_urls = ['https://www.gushiwen.cn/default_1.aspx' ] def myprint (self,value ): print ("=" *30 ) print (value) print ("=" *30 ) def parse (self, response ): gsw_divs = response.xpath("//div[@class='left']/div[@class='sons']" ) for gsw_div in gsw_divs : title = gsw_div.xpath(".//b/text()" ).get() source = gsw_div.xpath(".//p[@class='source']/a/text()" ).getall() dynasty = source[0 ] writer = source[1 ] self .myprint(source) content = gsw_div.xpath(".//div[@class='contson']//text()" ).getall() content = '' .join(content).strip()
你可以在任意地方插入self.myprint(内容)来进行打印,以验证数据是否被成功提取
接下来就是保存数据,我们先在items.py中配置好要保存的数据有哪些。
items.py还记得这个文件是干什么用的吗?
items.py:用来提前定义好需要下载的数据字段 。
一共有上述四部分内容需要保存,因此我们的items.py应该这样写:
1 2 3 4 5 6 7 import scrapyclass GswTestItem (scrapy.Item): title = scrapy.Field() dynasty = scrapy.Field() writer = scrapy.Field() content = scrapy.Field()
其中Field()可以理解为一种普适的变量类型 ,不管是字符串还是列表,都用scrapy.Field()来接收。
gsw_spider.py里导入items定义完items.py后,我们在gsw_spiders.py里导入 它。需要注意的是,gsw_spiders.py在spiders文件夹里,也就是说items.py在gsw_spiders.py的上层目录 中:
因此导入时,应该这样写:
1 from ..items import GswTestItem
导入后,我们将对应参数传入,然后使用yield关键字进行返回
1 2 item = GswTestItem(title=title,dynasty=dynasty,writer=writer,content=content) yield item
pipelines.py和settings.py先在settings.py里把pipelines.py打开:
1 2 3 4 5 6 ITEM_PIPELINES = { 'gsw_test.pipelines.GswTestPipeline' : 300 , }
再编写pipelines.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 from itemadapter import ItemAdapterimport json class GswTestPipeline : def open_spider (self,spider ): self .fp = open ("古诗文.txt" ,'w' ,encoding='utf-8' ) def process_item (self, item, spider ): self .fp.write(json.dumps(dict (item),ensure_ascii=False )+'\n' ) return item def close_spider (self,spider ): self .fp.close()
上面的open_spider函数和close_spider函数虽然不是自带的,但它是一种模版化的函数(套路) ,是一种Scrapy框架提供的高效的文件存储形式。
我们自己写的时候,只要按上述样式编(默)写即可,根据自己的需求修改存储文件的文件名、格式和编码方式,但不能改变两个函数名!
现在我们运行start.py,就会发现路径下多了一个古诗文.txt,打开以后是这样:
至此,第一页爬取成功!(不要在意为什么只爬了一点就结束了,先往下看,最后会有修正)
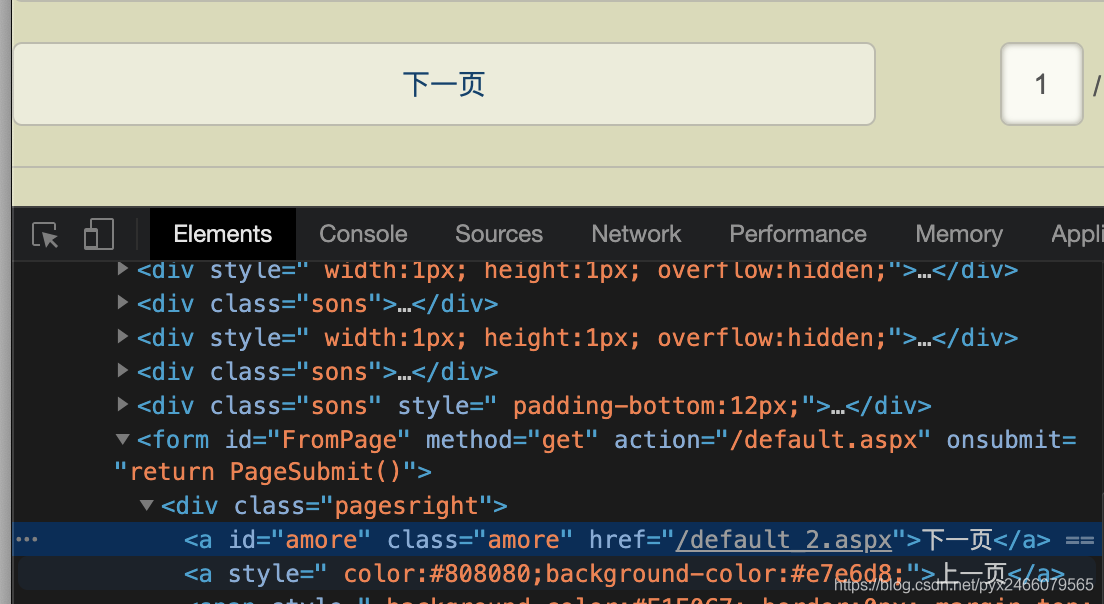
爬取了第一页的内容以后,我们还需要继续往后寻找,先来找一下第二页的url:
右键检查“下一页”按钮以获取下一页的url
为了测试寻找下一页的功能,我们暂时忽略之前的代码
1 2 3 4 def parse (self, response ): next_href = response.xpath("//a[@id='amore']/@href" ).get() next_url = response.urljoin(next_href) self .myprint(next_url)
找到了!
接下来我们就用一个request来接收scrapy.Request(next_url)的返回值,并使用yield关键字来返回即可:
1 2 3 4 next_href = response.xpath("//a[@id='amore']/@href" ).get() next_url = response.urljoin(next_href) request = scrapy.Request(next_url) yield request
需要注意的是,我们需要给“寻找下一页”操作设立一个终止条件 ,当下一页不存在 的时候停止访问,所以最后的代码长这个样子:
1 2 3 4 5 6 next_href = response.xpath("//a[@id='amore']/@href" ).get() if next_href: next_url = response.urljoin(next_href) request = scrapy.Request(next_url) yield request
此时我们的代码是这样的:
gsw_spider.py
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 import scrapyfrom ..items import GswTestItemclass GswSpiderSpider (scrapy.Spider): name = 'gsw_spider' allowed_domains = ['https://www.gushiwen.org' ] start_urls = ['https://www.gushiwen.cn/default_1.aspx' ] def myprint (self,value ): print ("=" *30 ) print (value) print ("=" *30 ) def parse (self, response ): gsw_divs = response.xpath("//div[@class='left']/div[@class='sons']" ) for gsw_div in gsw_divs : title = gsw_div.xpath(".//b/text()" ).get() source = gsw_div.xpath(".//p[@class='source']/a/text()" ).getall() dynasty = source[0 ] writer = source[1 ] content = gsw_div.xpath(".//div[@class='contson']//text()" ).getall() content = '' .join(content).strip() item = GswTestItem(title=title,dynasty=dynasty,writer=writer,content=content) yield item next_href = response.xpath("//a[@id='amore']/@href" ).get() if next_href: next_url = response.urljoin(next_href) request = scrapy.Request(next_url) yield request
运行后,会报这样一个错误:IndexError: list index out of range,意思是“列表的下标索引超过最大区间 ”。
为什么会有这样的错误呢?
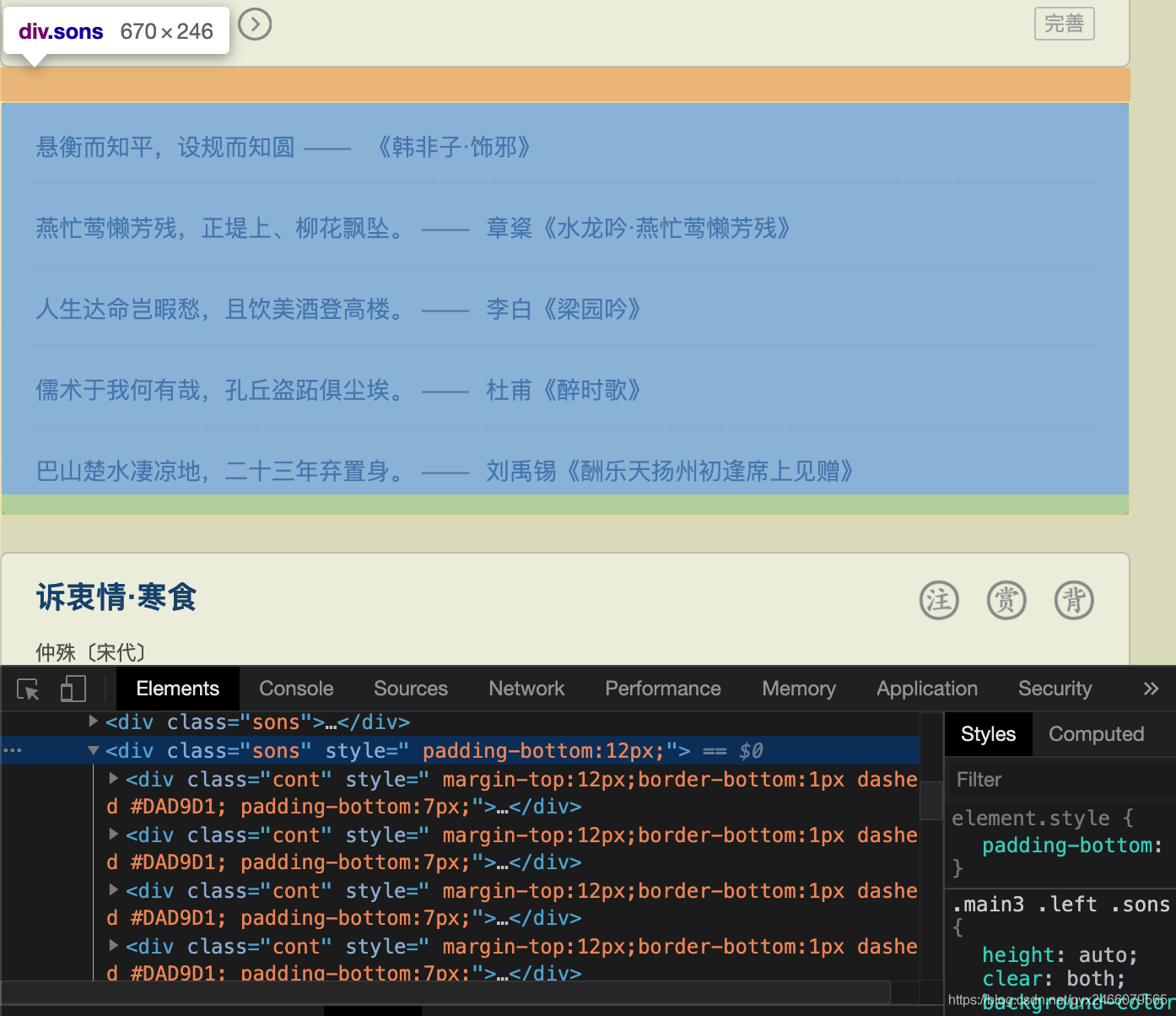
我们可以在网页上看到,页面上不全是古诗文:
除了古诗文外,这种短句子也是在class=sons的标签下,按照我们的查找方式:
1 2 3 gsw_divs = response.xpath("//div[@class='left']/div[@class='sons']" ) for gsw_div in gsw_divs : source = gsw_div.xpath(".//p[@class='source']/a/text()" ).getall()
找到图中蓝色的div标签以后,它里面是没有p标签的 ,也就是说此时的source是个空表 ,直接调用source[0]那必然是要报错的。
这算是网站的一种反爬虫机制 ,利用格式不完全相同的网页结构来让你的爬虫报错,太狠了!!
为了解决这个问题,我们添加try...except结构如下:
1 2 3 4 5 6 7 8 9 10 11 12 for gsw_div in gsw_divs : title = gsw_div.xpath(".//b/text()" ).get() source = gsw_div.xpath(".//p[@class='source']/a/text()" ).getall() try : dynasty = source[0 ] writer = source[1 ] content = gsw_div.xpath(".//div[@class='contson']//text()" ).getall() content = '' .join(content).strip() item = GswTestItem(title=title,dynasty=dynasty,writer=writer,content=content) yield item except : print (title)
这样,上面的报错就被完美解决了。
然鹅,一波未平一波又起,bug永远是生生不息源源不绝的
我们发现了一个新的报错:DEBUG: Filtered offsite request to 'www.gushiwen.cn': <GET https://www.gushiwen.cn/default_2.aspx>
这是因为我们在最开始的allowed_domains里限制了访问的域名:“https://www.gushiwen.org ”
而到了第二页的时候,网站偷偷把域名换成.cn了!
.cn不是.org,我们的爬虫没法继续访问,所以就停了。这又是这个网站的一个反爬虫机制,我们只需要在allowed_domains里添加一个.cn的域名,这个问题就可以得到妥善的解决:
1 allowed_domains = ['gushiwen.org' ,'gushiwen.cn' ]
运行可得到期望结果:
gsw_spider.py1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import scrapyfrom ..items import GswTestItemclass GswSpiderSpider (scrapy.Spider): name = 'gsw_spider' allowed_domains = ['gushiwen.org' ,'gushiwen.cn' ] start_urls = ['https://www.gushiwen.cn/default_1.aspx' ] def myprint (self,value ): print ("=" *30 ) print (value) print ("=" *30 ) def parse (self, response ): gsw_divs = response.xpath("//div[@class='left']/div[@class='sons']" ) for gsw_div in gsw_divs : title = gsw_div.xpath(".//b/text()" ).get() source = gsw_div.xpath(".//p[@class='source']/a/text()" ).getall() try : dynasty = source[0 ] writer = source[1 ] content = gsw_div.xpath(".//div[@class='contson']//text()" ).getall() content = '' .join(content).strip() item = GswTestItem(title=title,dynasty=dynasty,writer=writer,content=content) yield item except : print (title) next_href = response.xpath("//a[@id='amore']/@href" ).get() if next_href: next_url = response.urljoin(next_href) request = scrapy.Request(next_url) yield request
items.py1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import scrapyclass GswTestItem (scrapy.Item): title = scrapy.Field() dynasty = scrapy.Field() writer = scrapy.Field() content = scrapy.Field()
pipelines.py1 2 3 4 5 6 7 8 9 10 11 12 13 from itemadapter import ItemAdapterimport jsonclass GswTestPipeline : def open_spider (self,spider ): self .fp = open ("古诗文.txt" ,'w' ,encoding='utf-8' ) def process_item (self, item, spider ): self .fp.write(json.dumps(dict (item),ensure_ascii=False )+'\n' ) return item def close_spider (self,spider ): self .fp.close()
settings.py为了看起来简洁一点,注释部分我就都删了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 BOT_NAME = 'gsw_test' SPIDER_MODULES = ['gsw_test.spiders' ] NEWSPIDER_MODULE = 'gsw_test.spiders' ROBOTSTXT_OBEY = False DEFAULT_REQUEST_HEADERS = { 'Accept' : 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8' , 'Accept-Language' : 'en' , 'user-agent' : '我的user-agent' } ITEM_PIPELINES = { 'gsw_test.pipelines.GswTestPipeline' : 300 , }
大功告成!自己试一下吧!