使用爬虫采集数据时,常常会因为同一IP过于频繁的请求数据,导致IP被封禁。因此,使用代理IP轮换请求,可以降低被封的风险,提高数据采集的效率和稳定性。
本文以青果代理IP为例 (青果打钱!) 演示使用短效代理采集数据的方法:
获取API
首先,进入青果网络,点击右上角「注册」,并完成「个人实名认证」。
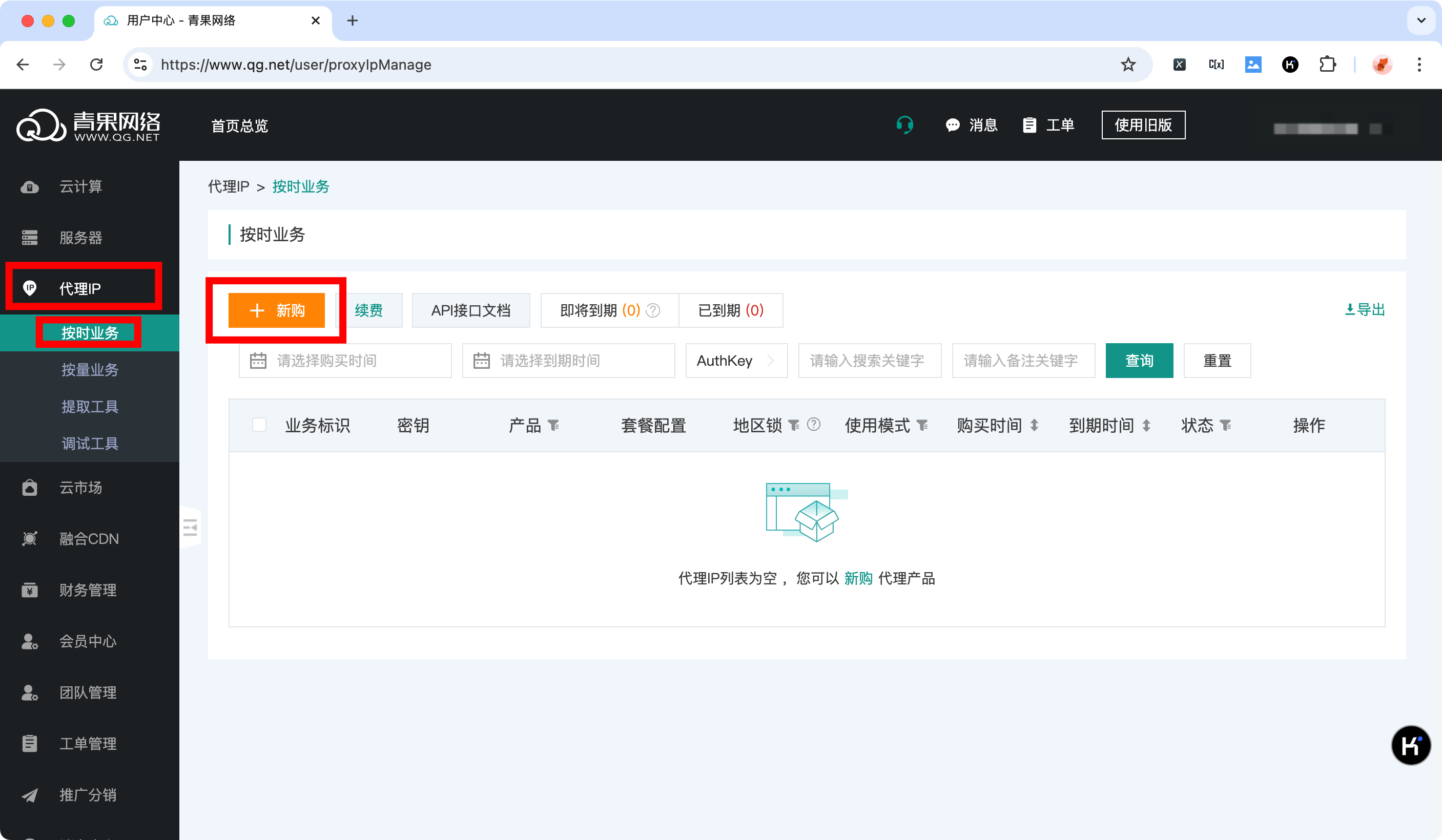
完成实名认证后,点击右上角「控制台」,从左边栏中选择「代理IP」,然后根据实际工程的需要选择一个代理类型,本文选择「按时业务」,点击「+新购」。
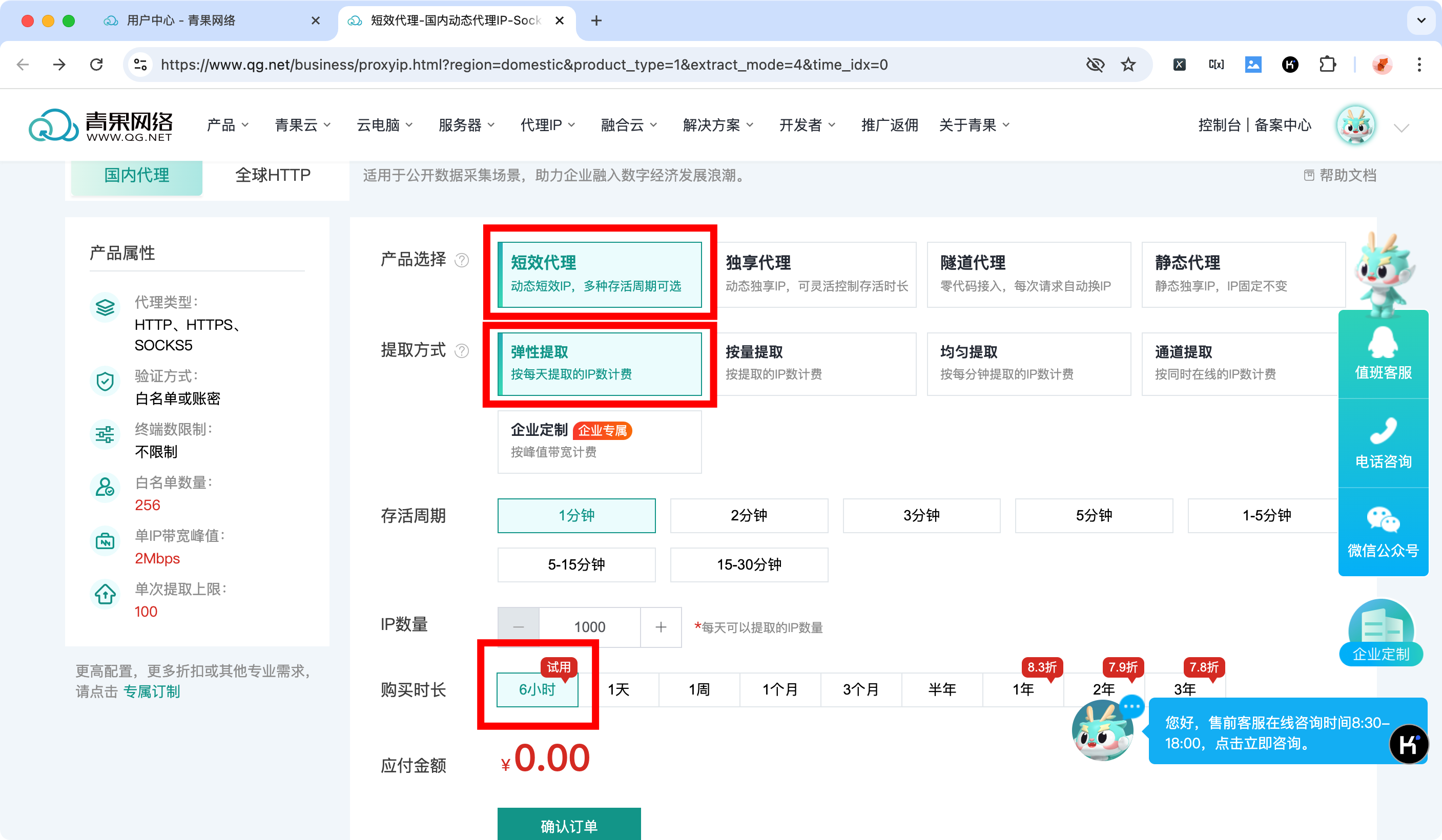
青果IP为新用户提供6小时的免费测试,直接点击「确认订单」:
好像6小时的免费可以重复获取,不用担心第一次练习失败以后产生经济损失。
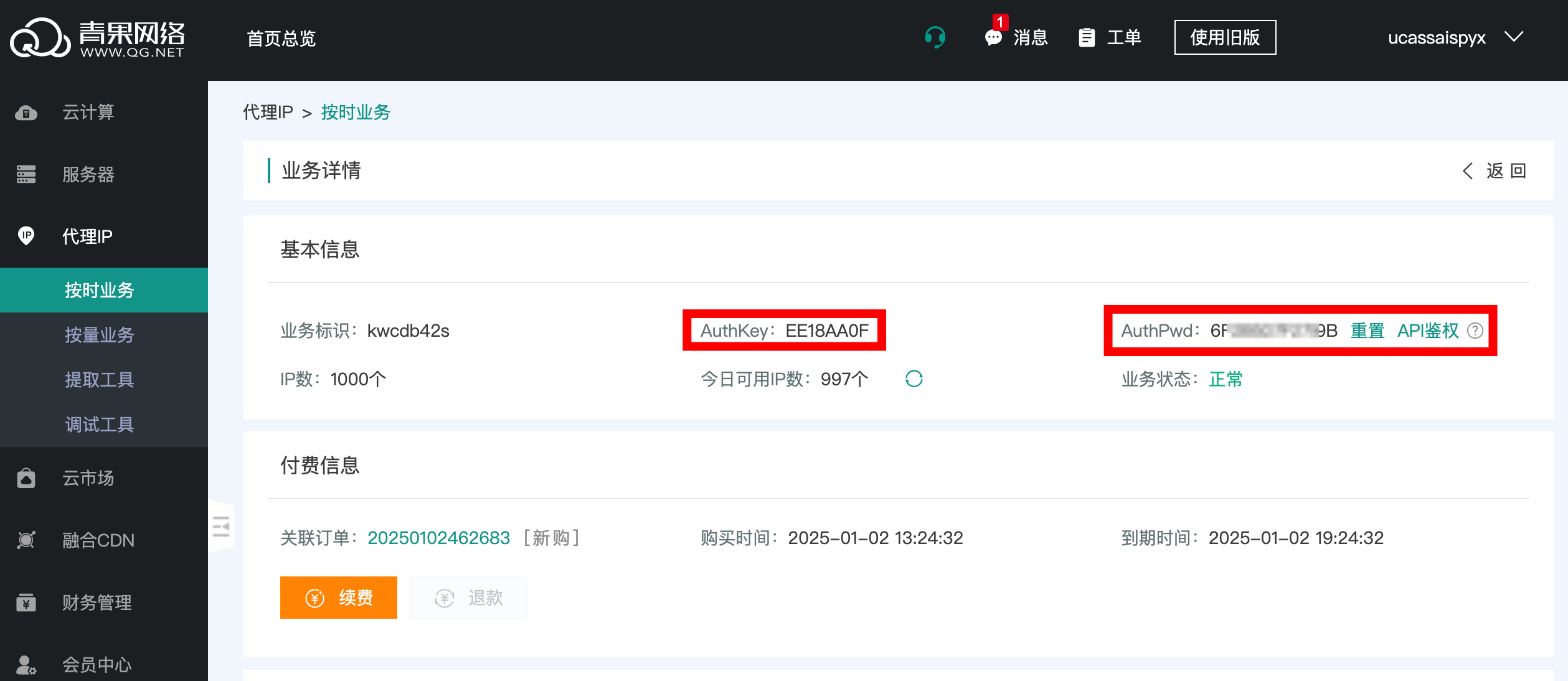
购买成功后,点击「产品管理」,记录当前页面的 AuthKey 和 AuthPwd:
其中, AuthKey 在提取和使用代理 IP 的过程中都会用到,AuthPwd 在使用的过程中会用到。
请求IP
关于IP的请求,可以参考官网给出的技术文档:
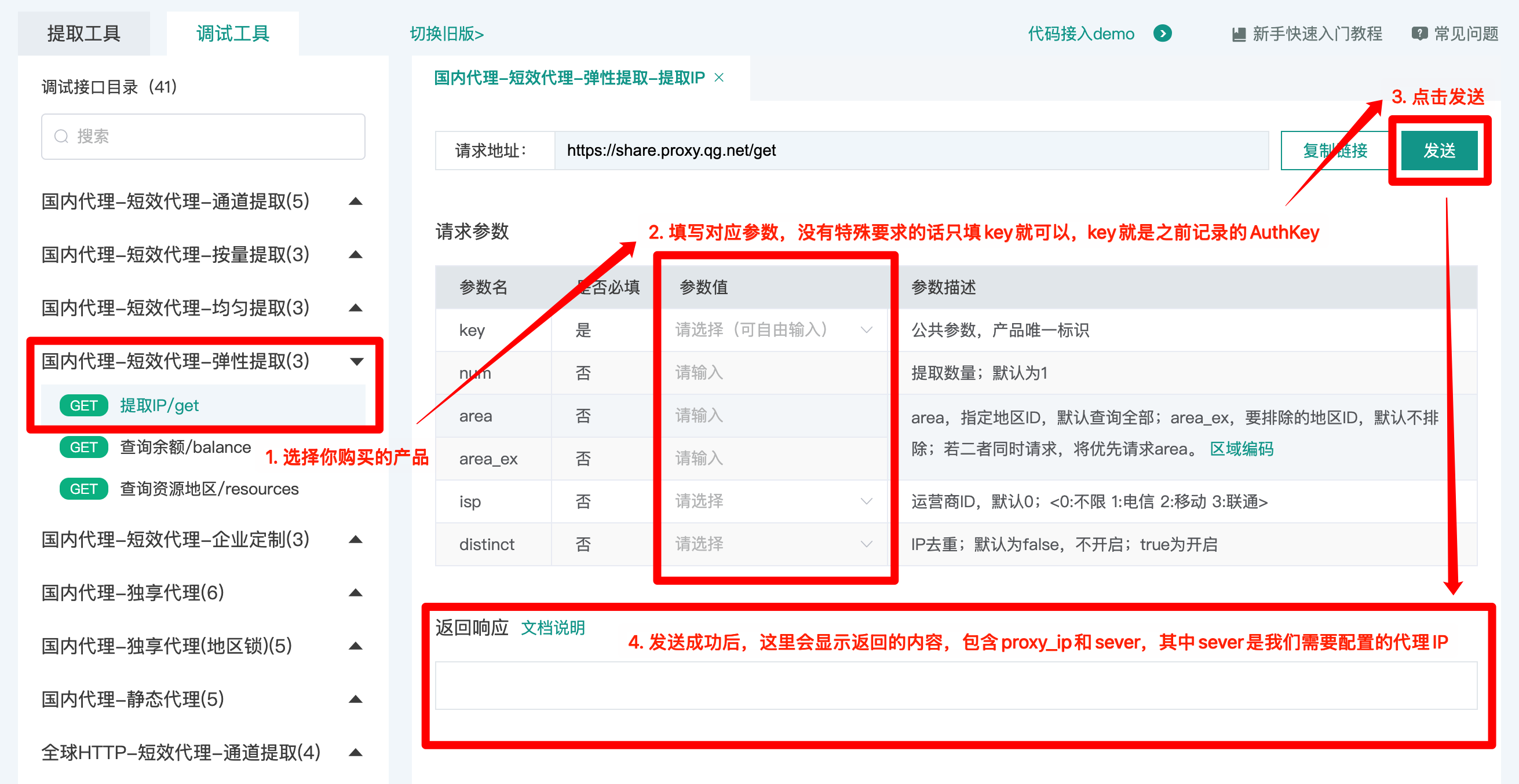
官方还提供了一个在线 DEBUG 工具,进入页面后按照你购买的产品选择对应调试工具:
为了便于后续使用,我们将它封装成一个函数:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| import requests
def get_ip(key, num=1, distinct=False):
proxyUrl = "https://share.proxy.qg.net/get?key=%(key)s&num=%(num)s&distinct=%(distinct)s" % {
"key": key,
"num": num,
"distinct": "true" if distinct else "false"
}
resp = requests.get(url=proxyUrl)
ip = resp.json()['data'][0]['server']
return resp, ip
|
实际工程中,你需要根据工程需要和API接口的要求,设置请求间隔等。
使用代理IP采集数据
官网给出了多种语法下的代码示例,可以参考:
以 requests 库为例,基本使用思路如下:
- 获取代理IP,这一步可以通过之前我们封装的
get_ip() 实现;
- 根据代理IP配置
requests.get() 方法的参数 proxies;
- 请求网页内容;
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| import requests
targetURL = "https://www.bilibili.com/"
authKey = "..."
password = "..."
_, proxyAddr = get_ip(authKey)
proxyUrl = "http://%(user)s:%(password)s@%(server)s" % {
"user": authKey,
"password": password,
"server": proxyAddr,
}
proxies = {
"http": proxyUrl,
"https": proxyUrl,
}
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/131.0.0.0 Safari/537.36',
'Cookie': "..."
}
resp = requests.get(targetURL, proxies=proxies, headers=headers)
print(resp.content.decode('utf-8'))
|
经过测试,可以成功请求Bilibili主页的内容。