有的数据明明在浏览器里可以看到,但使用 requests 库请求网页,却无法获得。
以 榜姐的点赞列表 为例,尝试直接请求该网页:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import requests
url = "https://m.weibo.cn/detail/5056551155145232#attitude"
headers = {
'Cookie': '自己的 cookie',
'User-Agent': '自己的 user-agent'
}
resp = requests.get(url, headers=headers)
text = resp.content.decode('utf-8')
print(text)
|
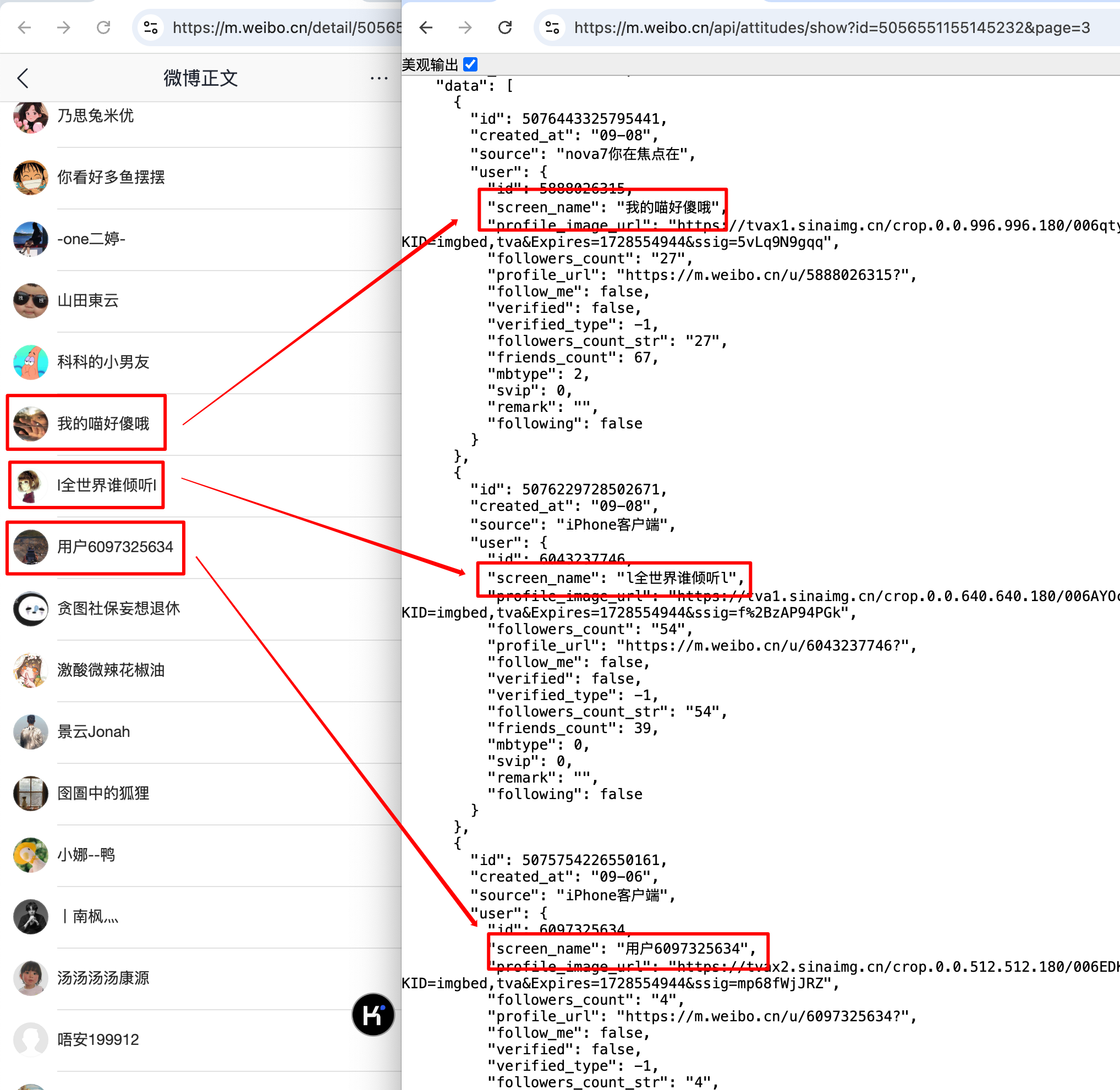
输出的内容中,并未包含点赞用户。
页面结构里没有的数据,却出现在了浏览器显示中,因此想要正确地获取这些数据数据,就要先明白 数据是如何进入页面的。
json文件获取
一般这类需要动态加载的数据,都是通过json文件发送到你的电脑上。
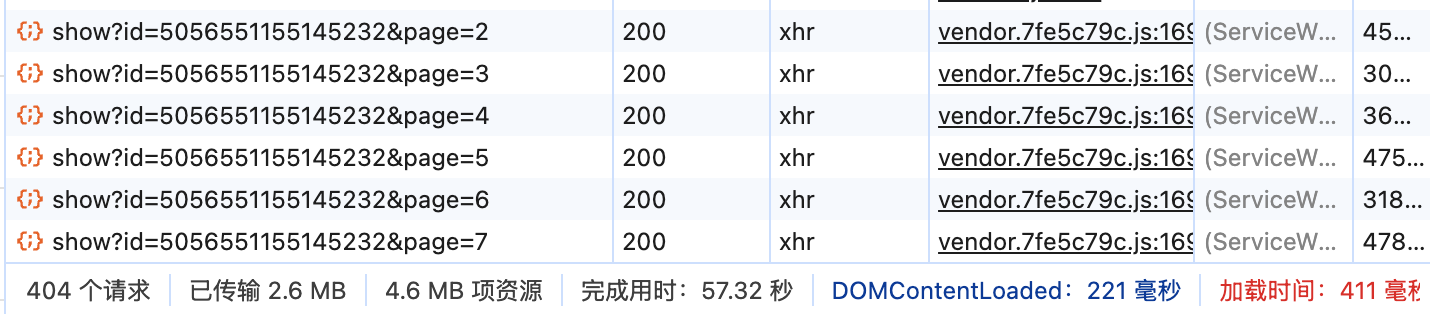
在谷歌浏览器中,进入检查模式(右键 - 检查),选择网络(Network)栏目,然后刷新网页,可以看到网络栏目中出现了很多条目:
按照 类型 排序,其中类型为 xhr 的就是json文件。
尝试滚动页面,并观察类型为 xhr 文件的变化,可以看出,下图中的文件在逐渐增多:
因此,我们大胆猜测,每次滚动页面时,新增的点赞数据都在这里面。
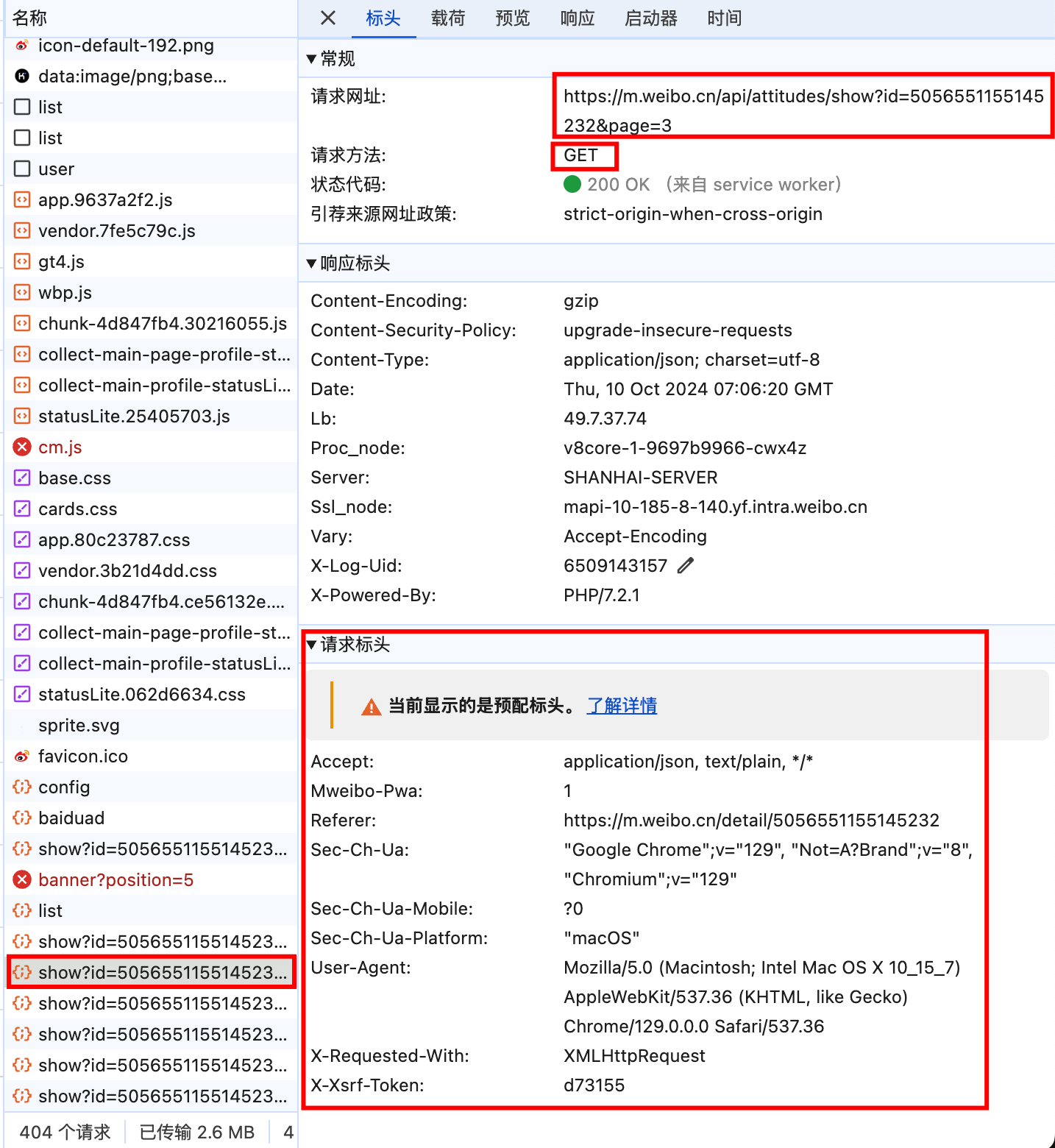
为了验证这一猜想,我们随便选择一个文件,鼠标左键单击,查看它的信息:
可以看出,它是由 get 请求得到的,网址为:
1
| https://m.weibo.cn/api/attitudes/show?id=5056551155145232&page=3
|
我们直接访问这一网址,看看其中的内容:
可以看出,点赞用户的数据确实出现在其中。
因此,我们只要 直接使用requests库的get方式请求这一网址,即可获得我们想要的点赞用户数据:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| import requests
url = "https://m.weibo.cn/api/attitudes/show?id=5056551155145232&page=3"
headers = {
'User-Agent': '你的 user-agnet'
}
resp = requests.get(url, headers=headers)
json_data = resp.json()
print(json_data)
|
至此,我们成功请求到了json文件,将其储存在电脑上。
1
2
3
4
5
| import json
with open('page3.json', 'w') as f:
json.dump(json_data, f, indent=4)
|
使用python解析json文件
json 文件可以理解为 字典和列表的嵌套,因此想要提取其中的数据,需要先借助大括号和方括号的位置,分析字典和列表的嵌套关系:
{ 表示里面的内容是一个字典,使用访问字典数据的方式提取其中的数据,如 key-value 方法[ 表示里面的内容是一个列表,使用访问列表数据的方式提取其中的数据,如索引方法
以我们刚刚获取的 json 文件为例:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| {
"ok": 1,
"msg": "...",
"data": {
"max": 4295,
"total_number": 214724,
"data": [
{
"id": 5076463254504741,
"created_at": "09-08",
"source": "Xiaomi 13",
"user": {
"id": 6347472563,
"screen_name": "...",
"profile_image_url": "...",
"followers_count": "31",
"profile_url": "...",
"follow_me": false,
"verified": false,
"verified_type": -1,
...
}
},
|
因此,如果我们想提取所有用户的 id 和 verified_type 这两个字段,需要:
1
2
3
| id_verified_dict = {}
for user_data in json_data['data']['data']:
id_verified_dict[user_data['user']['id']] = user_data['user']['verified_type']
|
*附:verified_type 的含义
| verified_type |
含义 |
verified_type |
含义 |
| -1 |
普通用户 |
6 |
应用 |
| 0 |
名人 |
7 |
团体、机构 |
| 1 |
政府 |
8 |
待审企业 |
| 2 |
企业 |
200 |
初级达人 |
| 3 |
媒体 |
220 |
高级达人 |
| 4 |
校园 |
400 |
已故 V 用户 |
| 5 |
网站 |
|
|
其中,verified_type=0 为黄 v,其他为蓝 v。
遍历爬取微博的点赞信息
在爬取数据之前,我们先在浏览器里 手动查看一下,可以发现最多只能查看 50 个 json 文件,这些文件的链接存在规律:
1
| https://m.weibo.cn/api/attitudes/show?id={博文id}&page={页面序号}
|
接下来,我们遍历地请求这些网站,并获取每个用户的 id 和 用户名:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
| import requests
import json
import random
import time
headers = {
'User-Agent': '你的 user-agent'
}
def getdata_by_blogid(blogid=5056551155145232):
id_username = {}
for page in range(1, 51):
url = "https://m.weibo.cn/api/attitudes/show?id={}&page={}".format(blogid, page)
resp = requests.get(url, headers)
json_data = resp.json()
for user_data in json_data['data']['data']:
id_username[user_data['user']['id']] = user_data['user']['screen_name']
sleep_time = random.uniform(1, 3)
print("blogid={},page={} 请求成功,{} 秒后继续.".format(blogid, page, sleep_time))
time.sleep(sleep_time)
return id_username
id_username = getdata_by_blogid()
|
实际数据采集过程中,可能会遇到一些问题,如页面请求失败、json 文件中没有对应路径、当前博文点赞数量较少(不到 page=50 就结束了)等,因此需要对代码做出优化如下:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
| import requests
import json
import random
import time
headers = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/129.0.0.0 Safari/537.36'
}
def getdata_by_blogid(blogid=5056551155145232):
id_username = {}
for page in range(1, 51):
url = "https://m.weibo.cn/api/attitudes/show?id={}&page={}".format(blogid, page)
resp = requests.get(url, headers)
if resp.status_code != 200:
page -= 1
sleep_time = random.uniform(5, 10)
print("blogid={},page={} 请求失败,{} 秒后重试.".format(blogid, page, sleep_time))
time.sleep(sleep_time)
continue
json_data = resp.json()
if json_data['ok'] == 0:
sleep_time = random.uniform(5, 10)
print("blogid={},page={} 请求结束,{} 秒后继续.".format(blogid, page, sleep_time))
time.sleep(sleep_time)
break
if json_data['ok'] != 1:
page -= 1
sleep_time = random.uniform(5, 10)
print("blogid={},page={} 请求失败,{} 秒后重试.".format(blogid, page, sleep_time))
time.sleep(sleep_time)
continue
for user_data in json_data['data']['data']:
id_username[user_data['user']['id']] = user_data['user']['screen_name']
sleep_time = random.uniform(1, 3)
print("blogid={},page={} 请求成功,{} 秒后继续.".format(blogid, page, sleep_time))
time.sleep(sleep_time)
return id_username
id_username = getdata_by_blogid()
|
以上就是通过请求 json 文件获取数据的基本方法。
通过 json 进行数据采集,属于较为高级的数据采集方法,掌握这一方法已经可以满足大部分数据采集的需求。