猫眼专业版实时票房数据获取
网址:http://piaofang.maoyan.com/dashboard
错误方法1:
1
2
3
4
| import requests
url = 'http://piaofang.maoyan.com/dashboard'
resp = requests.get(url)
print(resp.content.decode('utf-8'))
|
点开“检查网页源代码”,发现输出和源代码不一样
问题出在请求头上,连User-agent都没有,稍微走点心的网站都知道你是爬虫了
Ps.user-agent是什么:user-agent会告诉网站,访问者是通过什么工具来请求的,如果是爬虫请求,一般会拒绝;如果是用户浏览器,就会应答。我们在浏览器里获取的user-agent添加到爬虫中,网站检测这项数据时会把它当成你自己用的那个浏览器,以起到瞒天过海的作用。
错误方法2:
1
2
3
4
5
6
7
| import requests
url = 'http://piaofang.maoyan.com/dashboard'
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
}
resp = requests.get(url,headers=headers)
print(resp.content.decode('utf-8'))
|
这下输出和网页源代码一样了,兴高采烈找数据,发现没有!
原来是因为猫眼专业版的数据是实时更新的,因此它没有保存在静态的网页结构里,而是通过json文件实时发送,所以我们在网页源代码中是找不到数据的,数据在哪呢?
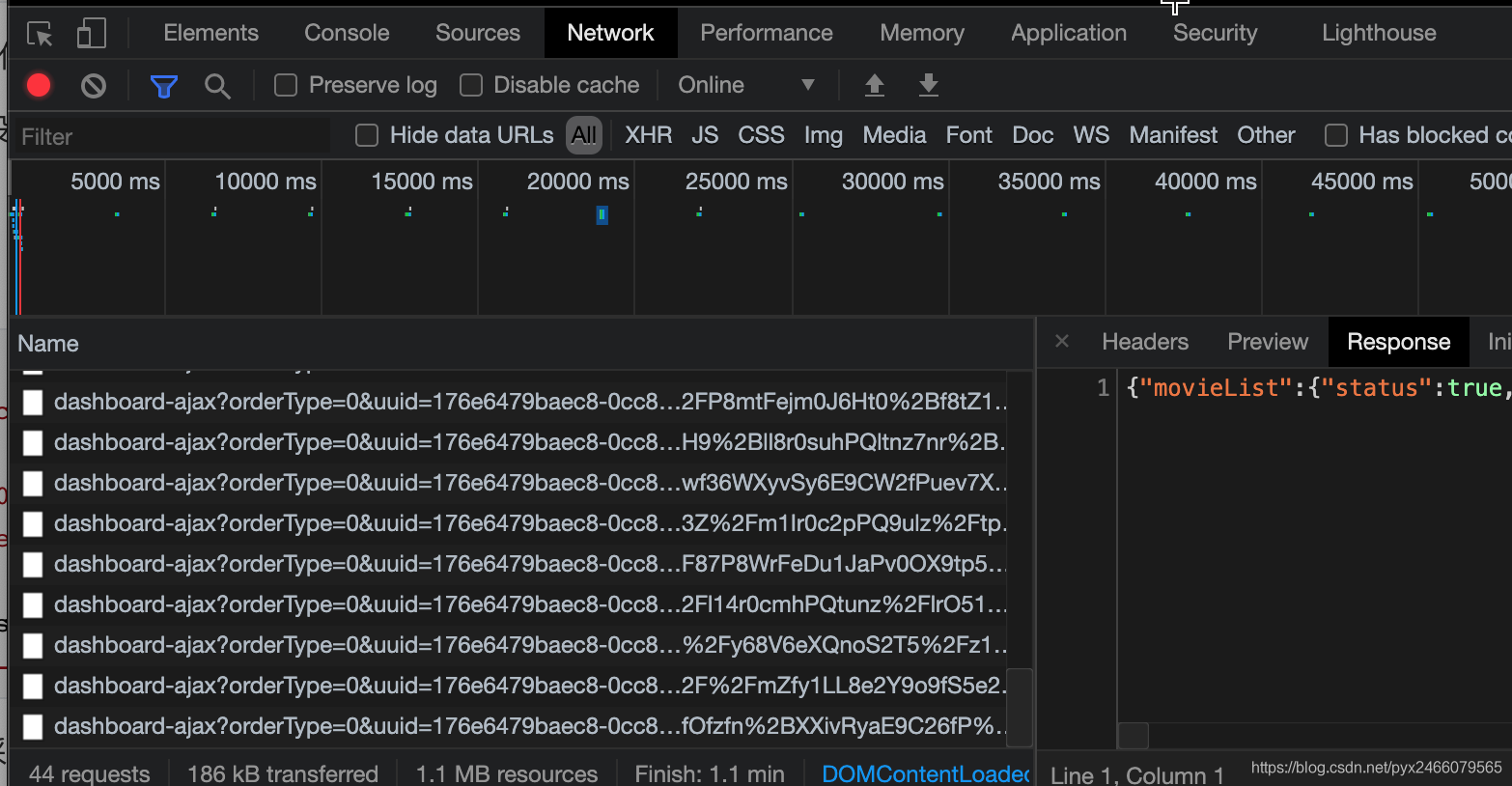
点开“检查”,在Network里你会发现,网页在不停的请求文件,选中右边的Response,仔细一找,数据就在里面!
当然,如果你觉得麻烦,这里推荐一个格式解析工具,可以自动把json文件里的代码以更美观的角度呈现。
在线的json解析工具:https://www.json.cn/
所以,我们请求静态网页的链接,是找不到数据的,而把链接换成发送数据包的链接,就可以得到数据了。
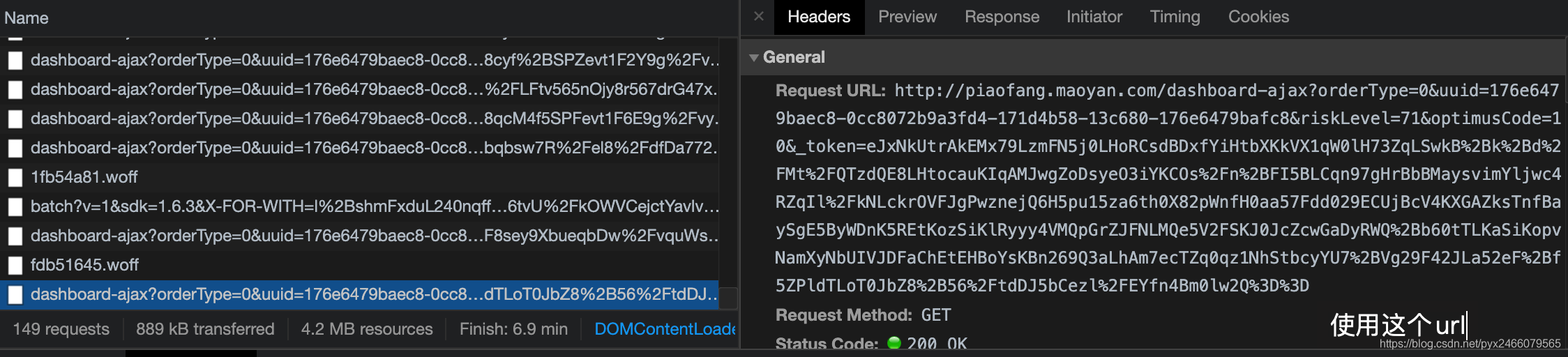
正确方法:
1
2
3
4
5
6
7
8
9
10
| import requests
url = 'http://piaofang.maoyan.com/dashboard-ajax?orderType=0&uuid=176e6479baec8-0cc8072b9a3fd4-171d4b58-13c680-176e6479bafc8&riskLevel=71&optimusCode=10&_token=eJxNkctqw0AMRf9l1sKRRvOyIYtAoaTQRUPaTchi8qgTSuLgmNJS%2Bu%2BVJi4tGO7x1cOS%2FGX6%2Bc40COZ935vGUIVVMGCGq2koEHmk6DlhALP98yySxTqC2fQvd6ZZEXECcdbqLMRYkXMINeIa%2FiGjPJozlxRzGIZLM5lcjrl7zee2OuXuM5%2BrbXea7PL1sOlyv5NJjBScllrAkQHF4RiBVJP0K8rgiyZIqjVDXTQBWQGHDigUiCNQDVZ7OGtHYAZbQhxGcBG4hLwF5gI1cAkFcaJCRHDlEzrDDTz4kixTeB3DI0PkAgGiVnkrB7mBBULdyTMBldG8XIvYKXnxSi8fZIGou%2Fmoh056lDc9imgedfh9f5T%2FKKnXY3sW2j98LJ%2Fb%2BWx2384WT9Op%2Bf4B3HBuKQ%3D%3D'
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
}
resp = requests.get(url,headers=headers)
print(resp.content.decode('utf-8'))
|
一些其他的动态网页,可能并不是实时更新,但也是采用同样的数据显示方式,这就需要你仔细的找一下数据到底藏在哪个文件里,点开Response后从上往下捋就行了。
当然你也可以使用selenium方法去模拟浏览器的行为,在这里就不细说了
石头阅读模拟登陆
石头阅读是一款免费的小说阅读器,书库覆盖面广,资源丰富,可以免费看各类需要付费的小说,堪称白嫖党的利器,趁此机会安利一下
网址:https://www.stoneread.com/
登陆在右上角,有点隐蔽:
模拟登陆大体上有两种,即添加cookie和使用post请求添加账号密码。由于后面的实战会涉及到前一种,所以这个实战就先用后一种了。
核心思路是,获取网站用以验证账号密码的url,然后把我们准备好的账号密码以post请求的形式发给它,这样就相当于登陆成功了。
怎么找目标url?
我们先手动登陆试试,点击登录后,注视着“检查”里的Network栏,你会发现一个“一闪即逝”的文件:
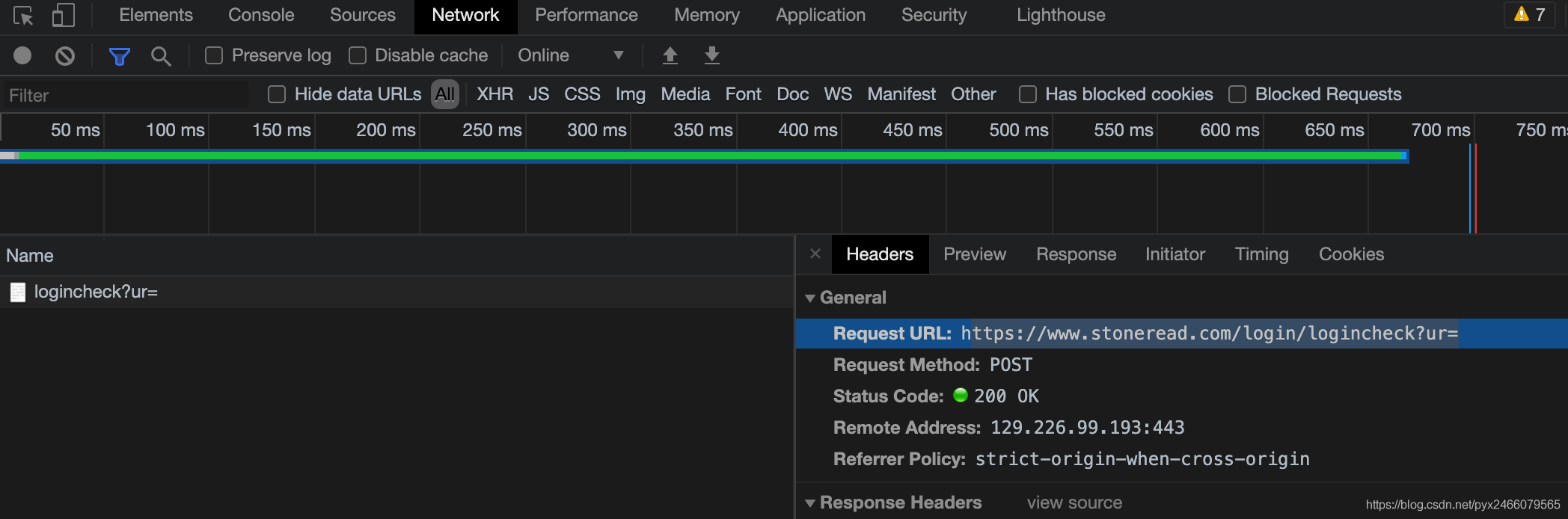
“小老弟,跑的挺快啊”
我们点击左上角的停止键,就可以获得这个文件,点开就有了url,顺便再抄一下user-agent
翻到下面,有一个“Form Data”,一看就是我们提交的账号密码:
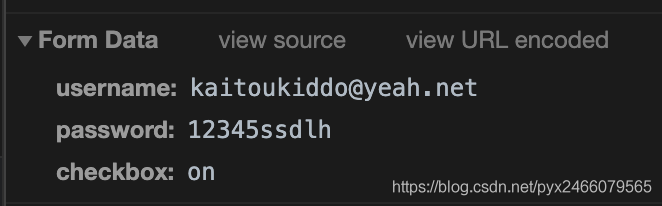
不许盗号!!!
这个checkbox代表的是那个“下次自动登录”选项,on自然就是表示“勾选”
代码:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
| import requests
url = 'https://www.stoneread.com/login/logincheck?ur='
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
}
data = {
'username' : 'kaitoukiddo@yeah.net',
'password' : '12345ssdlh',
'checkbox' : 'on'
}
resp = requests.post(url,headers=headers,data=data)
print(resp.content.decode('utf-8'))
|
结果中有“登陆成功”字样,和我们看到的页面一致。嘿嘿,成功啦~
设置代理ip
这个方法它成功几率不太大,因为我用的是免费的代理ip,没氪金怎么会变强呢它就不太稳定。我先把验证方法给一下。
获取免费ip的网址:
查看当前ip的请求url:http://www.httpbin.org/ip
ps. http://www.httpbin.org/是一个功能很强大的网站,大家可以访问一下康康
我们先不用代理,看一下自己的ip地址
1
2
3
4
| import requests
url = 'http://www.httpbin.org/ip'
resp = requests.get(url)
print(resp.text)
|
这个时候,就会打印出我自己电脑的真实ip
然后我们为它添加代理:
1
2
3
4
5
6
7
| import requests
proxy = {
'http':'111.77.197.127:9999'
}
url = 'http://www.httpbin.org/ip'
resp = requests.get(url,proxies=proxy)
print(resp.text)
|
这个时候如果你欧了一把,选的代理ip恰好是可以用的,那你就会看到程序打印出了你选的ip地址。
附:
-
urllib库设置代理的方法——ProxyHandler处理器
1
2
3
4
5
6
7
8
9
10
11
12
13
| from urllib import request
url = 'http://httpbin.org/ip'
handler = request.ProxyHandler({'http':'122.193.244.243:9999'})
opener = request.build_opener(handler)
resp = opener.open(url)
print(resp.read())
|
-
selenium设置代理的方法
1
2
3
4
| options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=htto://175.43.151.209:9999")
driver = webdriver.Chrome(executable_path="/Users/pangyuxuan/Desktop/chromedriver",chrome_options=options)
driver.get("http://httpbin.org/ip")
|
-
在Scrapy中设置代理
设置普通代理
1
2
3
4
5
6
7
8
| class IPProxyDownloadMiddleware(object):
PROXIES = [
"5.196.189.50:8080",
]
def process_request(self,request,spider):
proxy = random.choice(self.PROXIES)
print('被选中的代理:%s' % proxy)
request.meta['proxy'] = "http://" + proxy
|
设置独享代理
1
2
3
4
5
6
7
8
| class IPProxyDownloadMiddleware(object):
def process_request(self,request,spider):
proxy = '121.199.6.124:16816'
user_password = "970138074:rcdj35xx"
request.meta['proxy'] = proxy
b64_user_password = base64.b64encode(user_password.encode('utf-8'))
request.headers['Proxy-Authorization'] = 'Basic ' + b64_user_password.decode('utf-8')
|
爬取瓜子二手车交易信息
网址:https://www.guazi.com/www/buy/
我们先什么都不加,直接请求网址,看输出是什么,再逐渐的添加请求头里的内容,来尝试网站究竟是用什么作为反爬虫的检测依据的。
什么都不加:
1
2
3
4
5
| import requests
from lxml import etree
url = 'https://www.guazi.com/www/buy/'
resp = requests.get(url)
print(resp.text)
|
输出:

经过比较,它和网页源代码不一致,且最后还出现了乱码现象,说明text把解码方法猜错了——体现了content.decode('utf-8')的稳定性
添加User-agent:
1
2
3
4
5
6
7
8
| import requests
from lxml import etree
url = 'https://www.guazi.com/www/buy/'
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
}
resp = requests.get(url,headers=headers)
print(resp.content.decode('utf-8'))
|
哈哈!还是不行。
添加cookie:
1
2
3
4
5
6
7
8
9
| import requests
from lxml import etree
url = 'https://www.guazi.com/www/buy/'
headers = {
'Cookie' : 'uuid=8375fbff-6a87-4130-8c96-7a4aa8d30728; ganji_uuid=8329982395237678242215; cainfo=%7B%22ca_a%22%3A%22-%22%2C%22ca_b%22%3A%22-%22%2C%22ca_s%22%3A%22self%22%2C%22ca_n%22%3A%22self%22%2C%22ca_medium%22%3A%22-%22%2C%22ca_term%22%3A%22-%22%2C%22ca_content%22%3A%22-%22%2C%22ca_campaign%22%3A%22-%22%2C%22ca_kw%22%3A%22-%22%2C%22ca_i%22%3A%22-%22%2C%22scode%22%3A%22-%22%2C%22keyword%22%3A%22-%22%2C%22ca_keywordid%22%3A%22-%22%2C%22display_finance_flag%22%3A%22-%22%2C%22platform%22%3A%221%22%2C%22version%22%3A1%2C%22client_ab%22%3A%22-%22%2C%22guid%22%3A%228375fbff-6a87-4130-8c96-7a4aa8d30728%22%2C%22ca_city%22%3A%22qd%22%2C%22sessionid%22%3A%22dbe4532a-24f9-45fc-8c5f-b9518a2efb46%22%7D; antipas=93901707482fmWd51E58673WzOJ; cityDomain=www; clueSourceCode=%2A%2300; user_city_id=-1; preTime=%7B%22last%22%3A1611505261%2C%22this%22%3A1610175479%2C%22pre%22%3A1610175479%7D; sessionid=30370a7d-e999-43e4-a614-4ffacc7c8e75; lg=1; Hm_lvt_bf3ee5b290ce731c7a4ce7a617256354=1610175480,1610175573,1610524515,1611505262; Hm_lpvt_bf3ee5b290ce731c7a4ce7a617256354=1611505262',
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.96 Safari/537.36'
}
resp = requests.get(url,headers=headers)
print(resp.content.decode('utf-8'))
|
哈哈!竟然行了!
虽然我自己试的时候还额外添加了Host,但不知道为什么现在只加一个cookie就行了。
后续的思路就是我们通过“检查”,在Elements里找到详情页的链接如图:
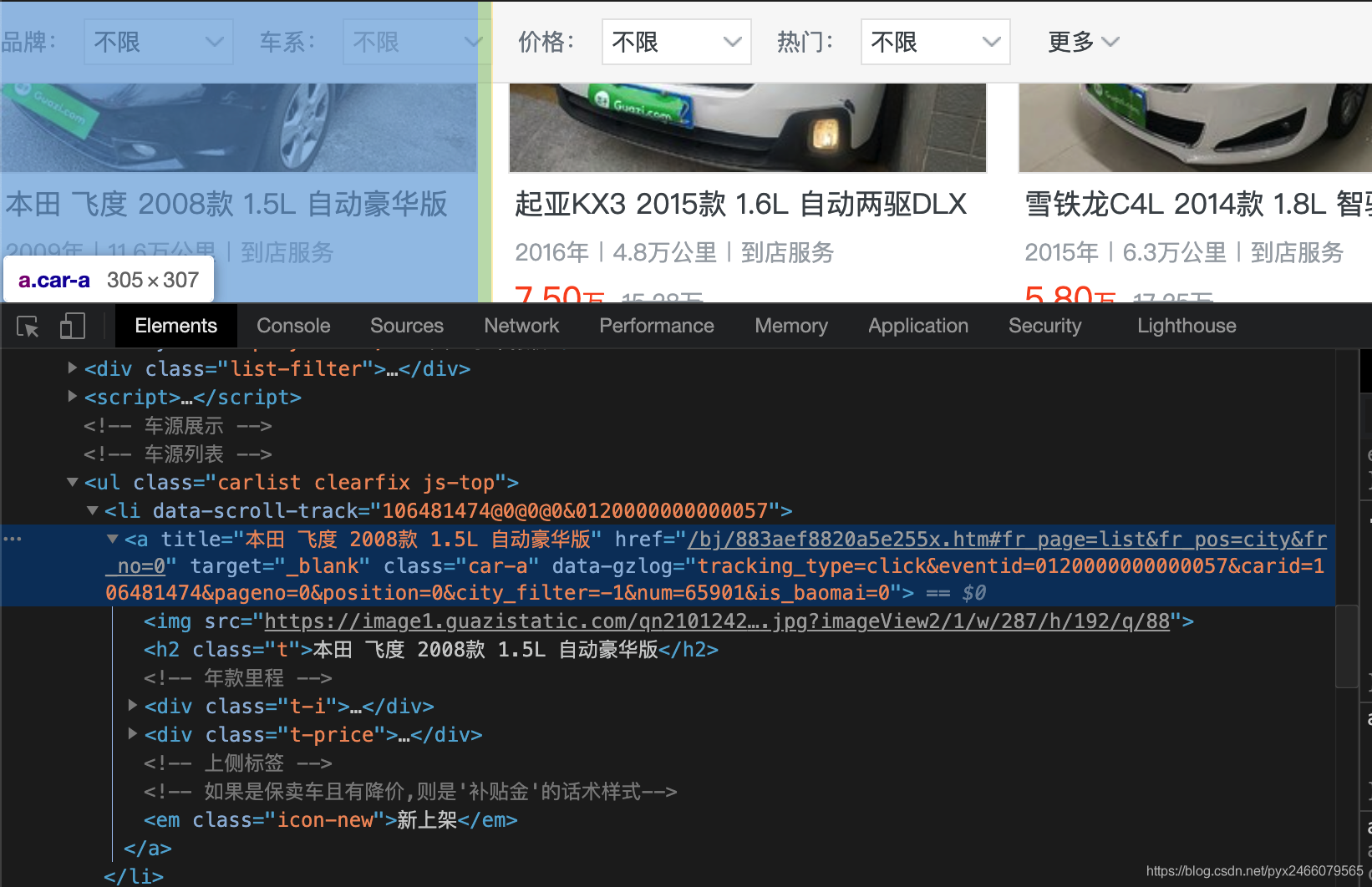
并且不同的车存放在不同的<li>标签中:
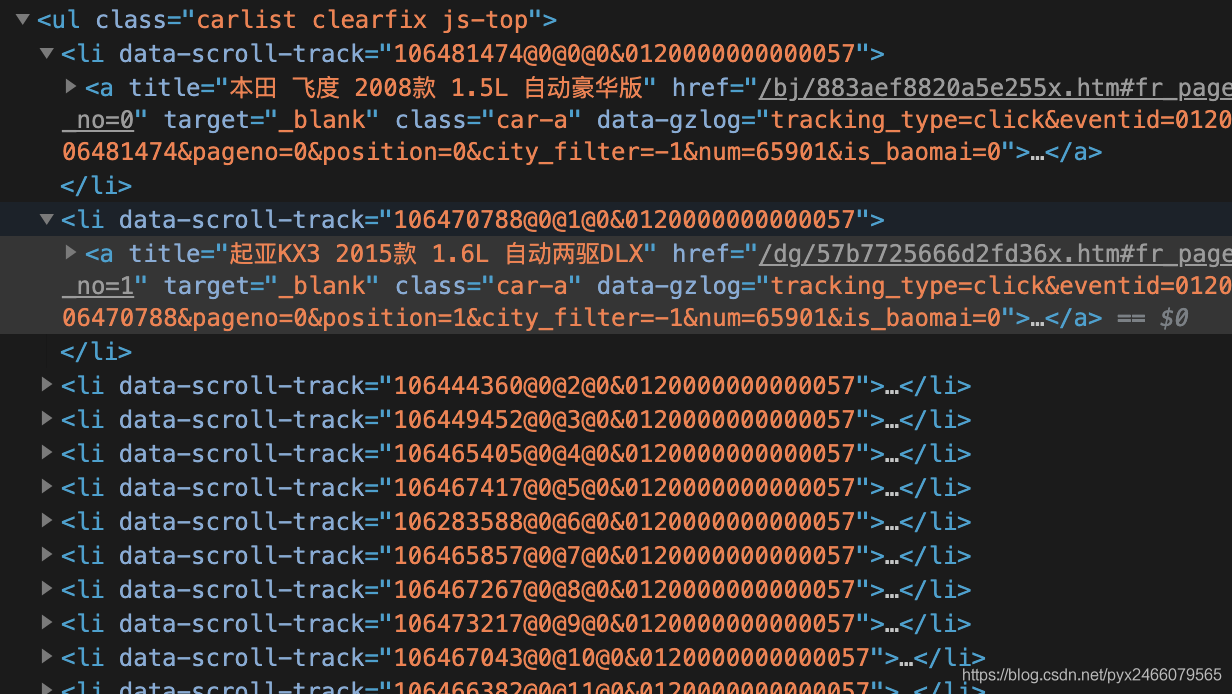
所以我们遍历所有<li>标签,依次访问每辆车的详情页面,再获取详情页面的车辆信息,进行存储即可。感兴趣的同学可以自行完成后面的代码,也可以找我要一下之前的代码
爬取豆瓣top250
网址:https://movie.douban.com/top250
这个案例也是我学习时候,花比较多时间做的一个案例,虽然它没有什么很惊艳的实现技巧,但我在做的时候遇到了这样一个问题:我被封号了!
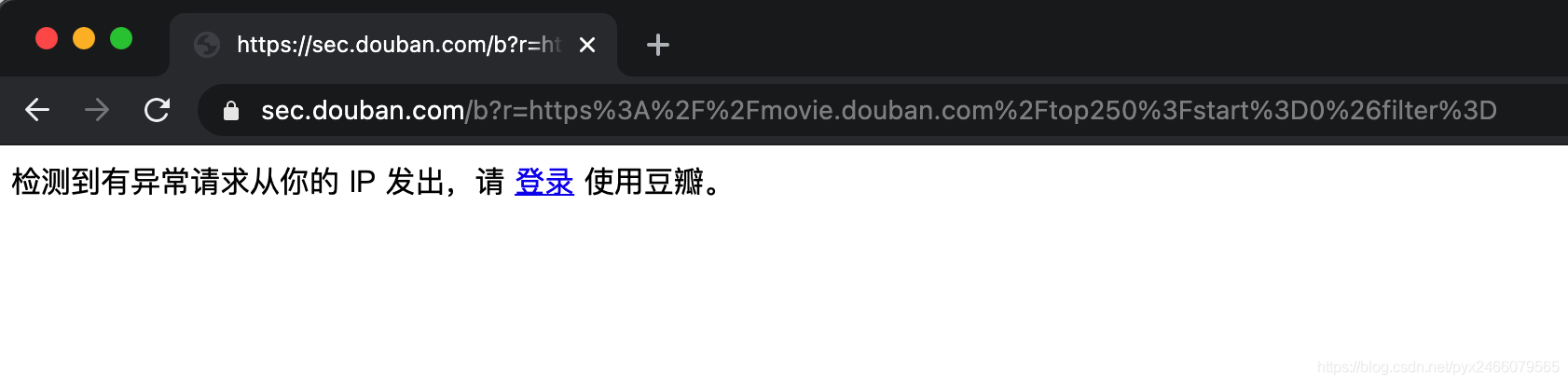
考虑到我囊中羞涩,没有租60r/月的代理服务器,而免费代理它又不太稳定,于是我选择老老实实的注册登陆。没错我就是前几天才注册豆瓣
很简单,只要登录以后添加cookie信息就可以了。
代码如下,做到存储数据之前:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
| import requests
from bs4 import BeautifulSoup
headers = {
'User-Agent' : 'Mozilla/5.0 (Macintosh; Intel Mac OS X 11_1_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/87.0.4280.141 Safari/537.36',
'Cookie' : 'll="118221"; bid=Dp60PRKNGWI; __yadk_uid=t4cy7TbKsr834lpYtjbt0Vn6au2yF7oP; _vwo_uuid_v2=D181BE4292803A62776208FF476CE0C21|403fd897a559fbd412c3a7530efb5d2f; __gads=ID=546d1adef9db7e77-221ec2b1c5c5000a:T=1611226743:RT=1611226743:S=ALNI_MZmgV9oiEJeTVAfAnDiNlwsRm8WMQ; ap_v=0,6.0; __utmc=30149280; __utmz=30149280.1611299250.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; __utmc=223695111; __utmz=223695111.1611299250.2.2.utmcsr=baidu|utmccn=(organic)|utmcmd=organic; _pk_ref.100001.4cf6=%5B%22%22%2C%22%22%2C1611302352%2C%22https%3A%2F%2Fwww.baidu.com%2Flink%3Furl%3DStwtEMgge76IHS2f9aoITF2La9KliUfVdz-ShjuHwB78oJQFmijIAnaCAMgiQfxo%26wd%3D%26eqid%3Dd8a7eb3b0003fac200000002600a79b0%22%5D; _pk_ses.100001.4cf6=*; __utma=30149280.233705150.1611225868.1611299250.1611302352.3; __utma=223695111.583107523.1611225868.1611299250.1611302352.3; __utmb=223695111.0.10.1611302352; dbcl2="231087110:rCDcDbFTf0I"; ck=rEkU; push_noty_num=0; push_doumail_num=0; __utmt=1; __utmv=30149280.23108; __utmb=30149280.2.10.1611302352; _pk_id.100001.4cf6=fcbcfa39023ea437.1611225868.3.1611304162.1611299286.'
}
def get_detail_urls(url):
resp = requests.get(url, headers=headers)
html = resp.text
soup = BeautifulSoup(html, 'lxml')
lis = soup.find('ol', class_='grid_view').find_all('li')
detail_urls = []
for li in lis:
detail_url = li.find('a')['href']
detail_urls.append(detail_url)
return detail_urls
def parse_detail_url(url):
resp = requests.get(url,headers=headers)
html = resp.text
soup = BeautifulSoup(html,'lxml')
lis = []
name = list(soup.find('span',property='v:itemreviewed').stripped_strings)
name = ''.join(name)
lis.append(name)
director = list(soup.find('div',id='info').find_all('span')[0].stripped_strings)
director = ''.join(director)
lis.append(director)
actor = list(soup.find('div',id='info').find('span',class_='actor').stripped_strings)
actor = ''.join(actor)
lis.append(actor)
score = soup.find('strong',class_='ll rating_num').string
lis.append(score)
remark = list(soup.find('span',property='v:summary').stripped_strings)
remark = ''.join(remark)
lis.append(remark)
print(lis)
def main():
base_url = 'https://movie.douban.com/top250?start={}&filter='
for x in range(0,251,25):
url = base_url.format(x)
detail_urls = get_detail_urls(url)
for detail_url in detail_urls:
parse_detail_url(detail_url)
if __name__ == '__main__':
main()
|
好家伙,我写这个文档时候,为了要上面那个“状态异常”的截图,把cookie删了以后疯狂爬取,直接导致我被封号了:

而且好像还没那么容易解锁。
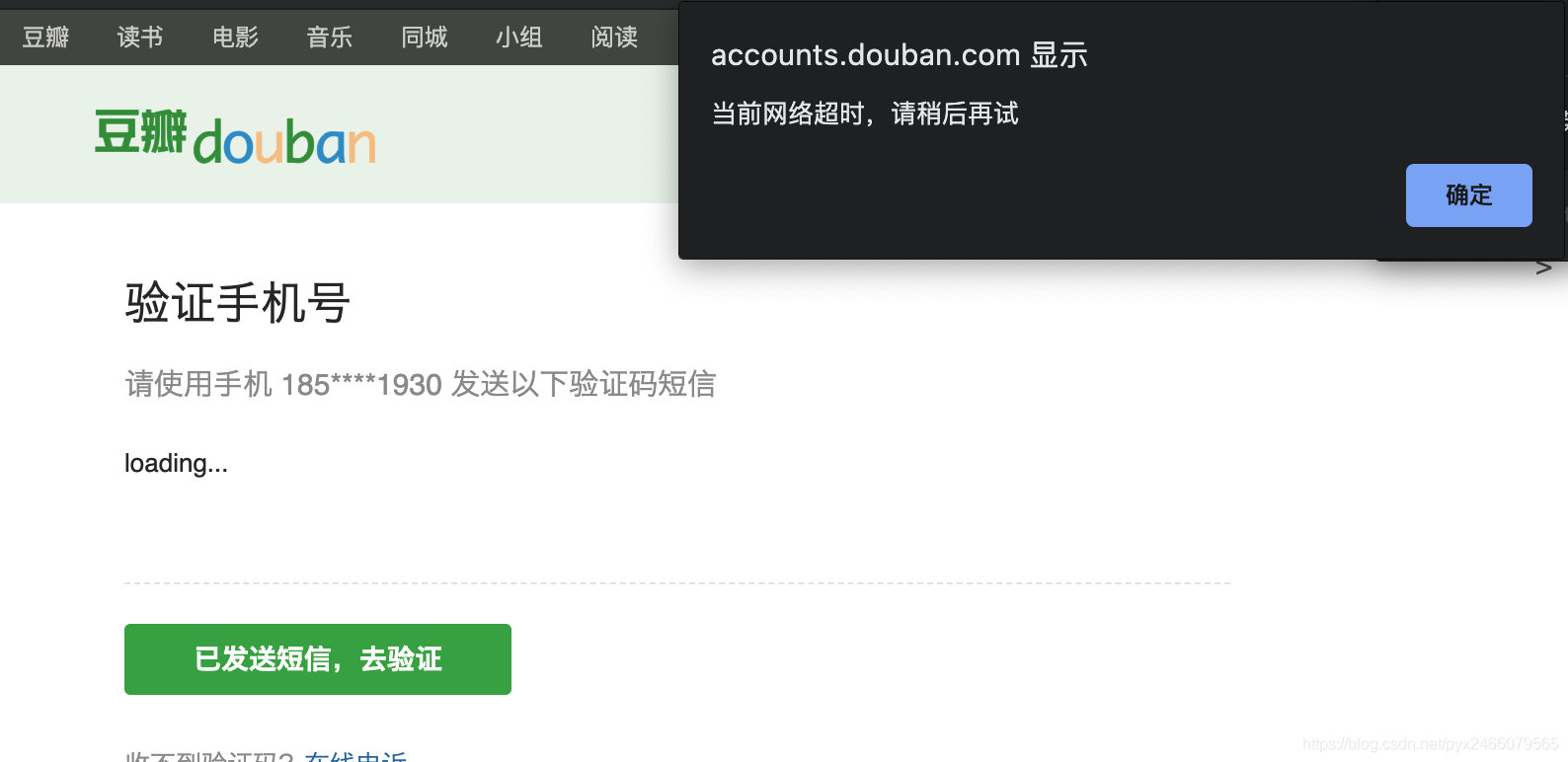
哎,先看最后一个吧
selenium行为链实战
有些厉害的网站会根据鼠标行为判断你是人还是爬虫,这个时候selenium库的行为链就可以帮你的爬虫躲过检查。因为我还没遇到这么牛逼的网站,所以就随便举个例子,说一下行为链的语法了。
比如我想在百度主页搜索“元尊”
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
driver = webdriver.Chrome(executable_path="/Users/pangyuxuan/Desktop/chromedriver")
driver.get("https://www.baidu.com/")
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'元尊')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
|
还有更多的鼠标相关的操作。
click_and_hold(element) :点击但不松开鼠标。
context_click(element) :右键点击。
double_click(element) :双击。
更多方法请参考:http://selenium-python.readthedocs.io/api.html
彩蛋:关于我被封号这件事


